

例題
僕が作った架空のデータで練習しましょう。結果についてはご意見があると思いますが、統計学の練習のためのサンプルですのでご了承ください。「母比率の検定」と書くべきところですが、理解しやすいようにここでは「比率の検定」というタイトルにしました。検定の前に二項分布について復習しておきましょう。

例題 1 「85歳以上」の転倒割合は、25.3%(約4人に1人)と報告されています(内閣府、平成17年)。この確率25.3%を転倒が起こる確率、つまり研究目的としている現象(転倒)が一般的に起こる確率 pとして進めます。S町に在住する85歳以上の高齢者10名のアンケート結果から、転倒経験ありと回答したのは6名であった(無作為抽出)。S町の85歳以上の高齢者の転倒割合は全国25.3%より高いと言えるか、有意水準5%で検証せよ! ・帰無仮説:S町の転倒割合は、全国割合(25.3%)に等しい ・対立仮説:S町の転倒割合は、全国割合(25.3%)より高い
上側検定
ある比率より大きいことを実証した場合には、上側検定を実施します(ここ重要)。この検定をRで実行する場合は、以下のようになります。
binom.test(
x=6, n=10, p=0.253,
alternative="greater"
)
上側検定なので alternative = “greater”
alternative hypothesis:対立仮説(Rは対立仮説を出力してくれるので分かりやすい)
p値は0.02となり(<0.05)、S町は全国に比べて転倒割合が有意に高いと言えます
検定の結果だけでよければ、ここまでで大丈夫です
ここからは少し詳しく勉強してみましょう
P値
ここから二項分布とP値について考えていきます
・帰無仮説:S町の転倒割合は、全国割合(25.3%)と等しい
・対立仮説:S町の転倒割合は、全国割合(25.3%)より高い
転倒回数を確率変数 $X$ と考えた場合、$X$ は二項分布に従う
\(X~B (10, 0.253)\)
この二項分布がどのようになっているのか・・・確率関数をグラフ化しましょう
面倒ですが、このような作業こそが”データサイエンスのお勉強”なのです。イメージを掴むことが大切ですね。
Rで確率分布のグラフを描いてみましょう
t <- 0:10
# Values of the probability function
p <- dbinom(
x=t, size=10, prob=0.253
)
# Bar plot (y-axis: values of the probability function)
barplot(
p ~ t, pch=16, xlab="", ylab=""
)
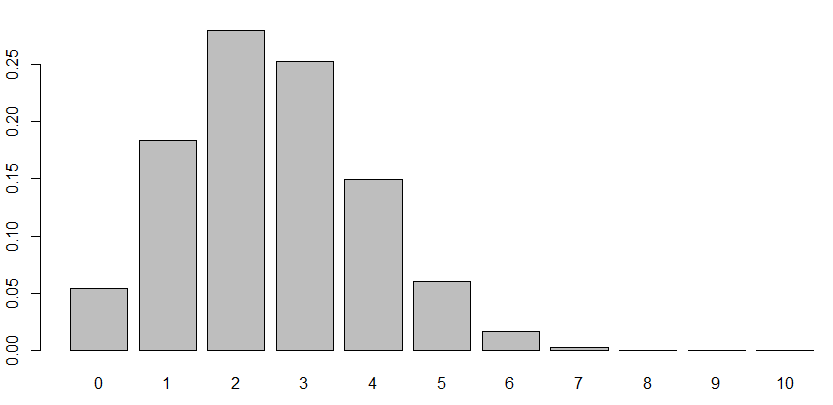
x軸は転倒回数、y軸は転倒回数が $x$ となる確率\(P(X=x)\)です。Rのdbinom関数は二項分布の確率関数から転倒回数ごとの確率を出力してくれます。

基準となる転倒確率が25.3%の場合、10回中6回転倒する確率\(P(X=6)\)は?
dbinom(
x=6, size=10, prob=0.253
)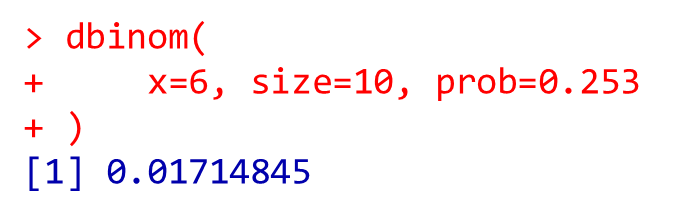
二項分布の確率関数に代入して確認してみましょう
サンプルサイズ $n=10$、転倒回数 $k=6$、基準となる転倒確立 $\pi=0.0253$
確率関数 \(P(X=k)={}_n C_kπ^k(1-π)^{n-k}\)
choose(10, 6)*(0.253^6)*(1-0.253)^4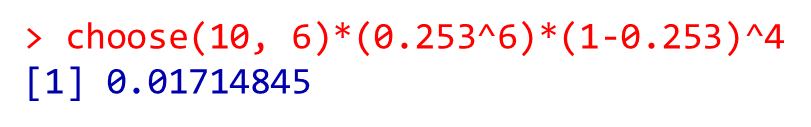
当然ですが同じ値になります(chooseは組合せの関数)。0.01714845は、以下のグラフの赤色の部分になります。
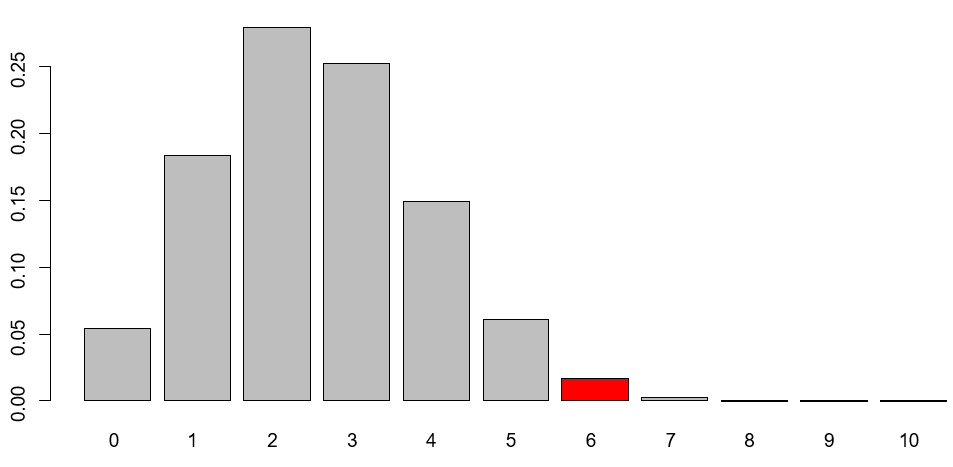
つまり基準となる転倒確率が25.3%の場合、「10回中6回転倒」という現象が起こる確率は約1.7%ということになります。それでは、次にp値を求めてみましょう(上側検定であることを忘れずに)。
p値 = 6回転倒する確率 + 7回転倒する確率 +・・・+ 10回転倒する確率
この確率が0.05を下回ればS町の転倒回数が高いことが統計学的に立証できます
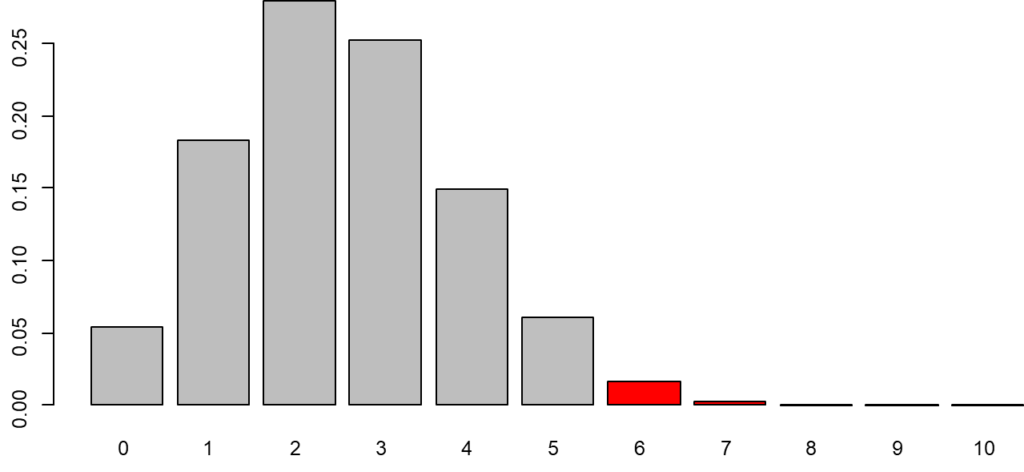
グラフの赤い部分の合計(p値)が0.05(有意水準)を下回れば帰無仮説が棄却されます
dbinom(x=6, size=10, prob=0.253) +
dbinom(x=7, size=10, prob=0.253) +
dbinom(x=8, size=10, prob=0.253) +
dbinom(x=9, size=10, prob=0.253) +
dbinom(x=10, size=10, prob=0.253)
Rで一気に求める場合
$\sum_{x=0}^5P(x)$ を算出して、lower.tail = FALSEとすることで $\sum_{x=6}^{10}P(x)$ となるp値(グラフの赤い部分)を算出します
pbinom(
q=5, size=10, prob=0.253,
lower.tail=FALSE
)もちろん答えは同じです。

下記のように書いても同じ意味です
1 - pbinom(
q=5, size=10, prob=0.253
)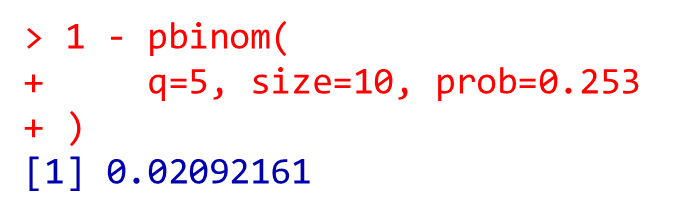
片側検定でも帰無仮説は棄却できませんでした。したがって、今回の調査ではS町の転倒割合は全国25.3%より有意に高いという結果になりました。
対立仮説の勝利 true probability of success is greater than 0.253
検定ですのでサンプルサイズが変われば結果は変わります
5人中4人が転倒する確率は $P(X=4) + P(X=5)$ を求めることになります
dbinom(
x=4, size=5, prob=0.253) +
dbinom(
x=5, size=5, prob=0.253
)
Rの関数を使用します
pbinom(
3, size=5, prob=0.253,
lower.tail=F
) 
やっぱり有意水準のみで検討することはよくありませんね。サンプルサイズや95%信頼区間などを考慮して結果をみんなで議論しましょう。