

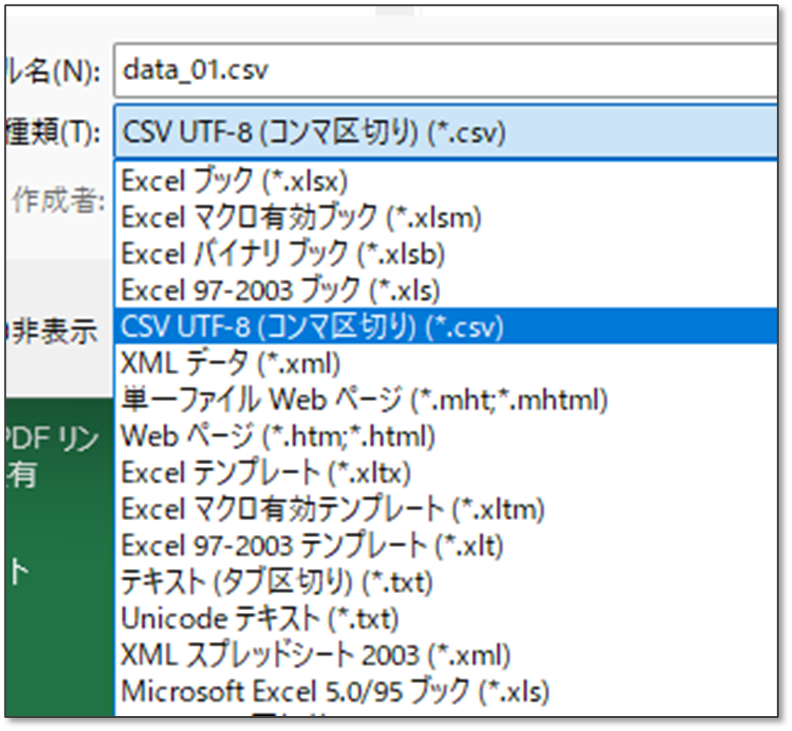
ファイルは必ず CSV に変換してください!
エクセルのファイル(.xlsx)は、「名前を付けて保存」を選択し、別途CSVファイルとして作成する必要がある。
csvを推奨する理由
1. 互換性が高い
2. 読み込みが高速
3. エラーが少ない
4. バージョン依存がない
サンプルのダウンロード
サンプルデータで練習してみましょう。まずは下のエクセルファイル(csvファイル) set01 をPCにダウンロード。
ファイルの読み込みは、最初の難関です。慣れるまではStep1~Step6をコピペして実行されることをお薦めします。特にstep6のパッケージのダウンロード先も指定しておいた方が後々便利です。
作業ディレクトリの指定とcsvファイルの読み込み
Step1: Rのリセット
以下のコードをRにコピー&ペーストすると、Rの環境がリセットされる。これにより、残っているすべてのオブジェクト(ベクトルやリストなど)が削除される。
rm(list = ls(all.names = TRUE))Step2: 作業するフォルダの指定
これからRを用いて解析を行う際には、まず作業するフォルダを設定する必要がある。このフォルダは「作業ディレクトリ(working directory)」と呼ばれる。Rは基本的にこの作業ディレクトリ内にあるCSVファイルなどのデータを読み込むため、あらかじめフォルダを指定しておくことが重要である。
作業ディレクトリとして「yoshidaのデスクトップにある練習用のフォルダ」を指定する方法を紹介する。
#Windowsの場合
setwd("C:/Users/yoshida/Desktop/練習用")
#Macの場合
setwd("/Users/yoshida/Desktop/練習用")R 3.2.0より以前のバージョンでは、パスを記述する際にバックスラッシュ(\)を2つ続けて記述する必要がある。
setwd("C:\\Users\\yoshida\\Desktop\\練習用")Step3: 作業するフォルダの確認
以下の関数を用いることで、step2で指定したフォルダの場所を確認することができる。step2の例のように設定した場合は、“C:\Users\yoshida\Desktop\練習用“ と出力される。
getwd()デスクトップを作業フォルダに設定している場合には、以下のように表示される。

練習用フォルダの中の確認
指定したフォルダの中に、サンプルデータ「set01」を入れる。また、練習用フォルダにファイル名「R練習用」のテキストファイルを入れておく。
list.files()
Step4: CSVファイルの読み込み
以下のコードをコピー&ペーストすると、ダウンロードした「set01」をdataの中に格納することができる。この操作によって、dataはデータフレームとなる。
data <- read.csv("set01.csv", header = T, fileEncoding = "UTF-8")文字化けなどが発生し、うまく読み込めない場合は、fileEncodingの指定を以下のように変更する。
fileEncoding = "Shift-JIS" 文字エンコーディングの規格は、UTF-8が世界標準になってきてるようです。UTF-8 と Shift-JIS の規格の違いについては、ネット検索またはChatGPT様に尋ねてみてください。
プロンプト
read.csvとread_csvの違いを教えてください
read.csv(utilsパッケージ)
Rの標準パッケージでutilsから提供。文字列はfactor型として読み込まれる(stringsAsFactors = TRUEがデフォルト設定であったが、R 4.0.0以降はstringsAsFactors = FALSEがデフォルトとなる)。区切り文字はカンマ(,)がデフォルト。ファイルのエンコーディングを指定は、fileEncoding。ヘッダー行があることを仮定(header = TRUEがデフォルト)。
read_csv(readrパッケージ)
read_csvはreadrパッケージに属する。tidyverseに含まれる。read_csvはデフォルトで文字列を文字列のまま読み込む(stringsAsFactorsオプションなし)。通常、read_csvの方がread.csvよりも読み込みが速いとされている。ファイルのエンコーディングはlocaleの引数を通じて設定。ヘッダー行があると仮定しますが、より多くの現代的なデータ処理機能を持っている。
Step5: CSVファイルが読み込まれたことを確認
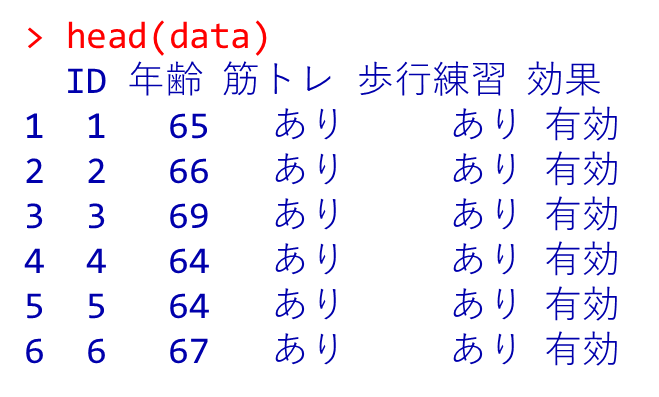
以下のコードを用いることで、set01が格納されているdataの先頭6行が表示される。
head(data)CSVファイルの先頭6行が表示されれば成功である。
データフレームを確認
View(data)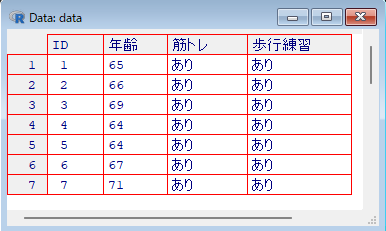
Step6: パッケージのダウンロード先の指定
パッケージをインストールして保管するフォルダを作成します。これから多くのパッケージをインストールすることになるので、同じフォルダに入るように指定しておきます。Rを更新したときも同じ場所から起動することができます。例えば・・・「yoshidaのドキュメントのPackagesフォルダ」であれば、、、
パッケージをインストールして保管するフォルダを作成する。今後、多くのパッケージをインストールすることになるため、同一のフォルダに格納されるようあらかじめ指定しておく必要がある。これにより、Rを更新した場合でも同じ場所から利用することが可能となる。例として、「yoshidaのドキュメントにあるPackagesフォルダ」を指定する方法は以下のようになる。
#Windows
.libPaths("C:/Users/yoshida/Documents/Packages")
#Mac
.libPaths("/Users/yoshida/Documents/Packages")R3.2.0より以前のバージョンでは バックスラッシュを2回(¥が2つ)書かなければなりません。
.libPaths("C:\\Users\\yoshida\\Documents\\Packages")