

単変量解析
年齢のヒストグラムを作成
hist(data$年齢)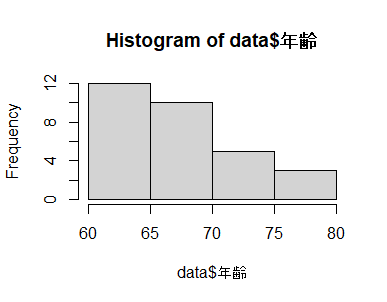
分布が偏っているため、対数変換したヒストグラムを作成してみる。
log_age <- log(data$年齢)
hist(log_age)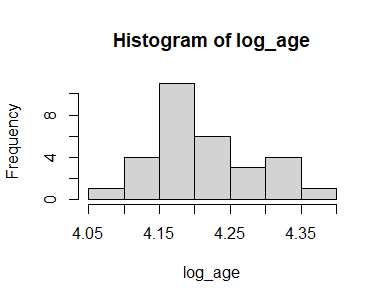
検定したら正規分布になっていないかもしれませんが、最終的にどのような解析で使用するかで変数の変換が必要になります。次のように2値に変換する場合もあります。set に 年齢c という変数を追加します。年齢c に条件を付けて2値にします:「年齢65歳未満を0、65歳以上を1」と記載します。
検定を行った結果、正規分布に従っていない可能性もあるが、最終的にどのような解析に用いるかによって、変数の変換が必要となる。このように、場合によっては次のように2値に変換することもある。setに「年齢c」という変数を追加し、年齢cに条件を設定して2値化する。すなわち、「年齢65歳未満を0、65歳以上を1」とする。
data$年齢c <- ifelse(
data$年齢 > 65, 0, 1
)datを確認すると、「年齢c」という列が追加されており、「年齢65歳未満を0、65歳以上を1」というルールに従った2値変数となっている。
head(data)
年齢65歳未満と65歳以上の人数
table(data$年齢c)
年齢65歳未満は 18名、65歳以上は 12名 であった
作業終了時のポイント
例)メモ帳に記録したプログラム
テキストエディタに記載したプログラムは同じ作業フォルダに保存する。
R練習用に必要なプログラムを記載しておけば、同じ解析を再現することができる。したがって、R終了時の「作業スペースを保存しますか?」という問いには、「いいえ」を選択して問題ない。
また作業したい場合
メモ帳(テキストエディタ)に記載したプログラムをRにペーストするだけで、同じ解析を再開することができる。ディレクトリの指定、パッケージの保管場所の指定、CSVファイルの読み込みといった一連の作業も瞬時に実行することが可能である。
これができるようになれば、エディタのみを保管しておけば問題ない。RがインストールされているPCであれば、いつでもどこでも作業を再開することが可能である。
職場と自宅の2台のPCを使用している場合
PCの名称が同じであれば、この設定は不要である。作業する場所はデスクトップを想定している。PCの名称が異なる場合は、以下のように2種類のディレクトリを作成する。R 3.2.0より以前のバージョンでは「\」を用いる必要がある(\が2つ必要である)。それぞれのPCのパスを記載し、いつでもどこでも利用できるように、USBやクラウドなどに保存しておくと便利である。
#職場のPCを使う場合
setwd("C:/Users/職場PC名 /Desktop/職場のフォルダ")
#自宅のPCを使う場合
setwd("C:/Users/自宅PC名 /Desktop/自宅のフォルダ") 設定が正しく行われたかどうかを確認する。繰り返しになるが、必ず確認する必要がある。
getwd()エラーが出なければセット完了である。自宅のフォルダにCSVファイルを入れ、Rで読み込む。
dat <- read.csv("set01.csv", header=T, fileEncoding = "UTF-8")