

F分布の導出(カイ二乗分布から)
F分布
F分布を理解するために,まずカイ二乗分布と標本分散の関係を確認する. 正規母集団から標本サイズ $n$ の無作為標本を抽出したとき,不偏分散 $S^2$ に対して
が成り立つ.
したがって,
と表すことができる.
すなわち,標本分散と母分散の比は, カイ二乗分布に従う確率変数を自由度で割った形として表される.
ここで,F分布とは,2つの独立なカイ二乗分布に従う確率変数の比から構成される分布である. すなわち,自由度 $k_1, k_2$ の独立な確率変数 $W_1, W_2$ が
に従うとき,
は自由度 $(k_1, k_2)$ のF分布に従う.
このとき,
と書けることから,F分布は分散の比を表す分布として解釈できる. さらに,帰無仮説 $\sigma_1^2 = \sigma_2^2$ のもとでは,
と表される.そのため,F分布は分散の比較に用いられ,特に2つの母分散が等しいかどうかの検定(分散比検定)や分散分析において重要な役割を果たす.
定義
$Y_1, Y_2$ を互いに独立なカイ二乗分布に従う確率変数として、それぞれの自由度を $k_1, k_2$ とする。
このとき,
は自由度 $(k_1, k_2)$ のF分布に従う:
正規母集団からF分布の導出
正規母集団からの標本に対して標本分散を考えると,その標準化された量がカイ二乗分布に従うことが知られている.カイ二乗分布は,標準正規分布に従う確率変数の二乗和として定義される.すなわち,独立な標準正規確率変数 $Z_1, \dots, Z_k$ に対して,
が成り立つ.
一方,不偏分散の定義より
であるから、
と書き換えることができる.
したがって,正規母集団からの標本に対しては,
がカイ二乗分布に従うことが知られている.
2つの独立な正規母集団からの標本を考える.
標本1:標本サイズ $n_1$,標本分散 $S_1^2$,母分散 $\sigma_1^2$
標本2:標本サイズ $n_2$,標本分散 $S_2^2$,母分散 $\sigma_2^2$
標本1について,次の確率変数を定義する:
不偏分散の関係より,
と書き換えられる.このとき,
が成り立つ.
同様に標本2について,
とすると,
な成り立つ.
また,標本が独立であるとき,$W_1$ と $W_2$ は独立である.
したがって,
ここに $W_1, W_2$ を代入すると,
したがって
が得られる.
分散の等質性の検定
帰無仮説
のもとでは
が成り立つ.
この結果を利用することで,2つの母分散が等しいかどうかを検定することができる.
例題
これまでの結果を用いて,分散の等質性の検定の例題を考える.
例題
血圧を測定した結果,A群($n_1 = 51$)の標本分散は $s_1^2 = 10$(mmHg$^2$),B群($n_2 = 31$)の標本分散は $s_2^2 = 5$(mmHg$^2$)であった.A群とB群の母分散は等しいと言えるかを,有意水準 $2.5\%$ の片側検定で検討せよ.
帰無仮説:母分散は等しい
対立仮説:A群の母分散 > B群の母分散
検定統計量
このとき,帰無仮説のもとで
が成り立つ.
p値の計算
判定
したがって,帰無仮説は棄却される.
結論:A群の母分散はB群の母分散よりも有意に大きいといえる.
グラフを用いて検定結果を解説
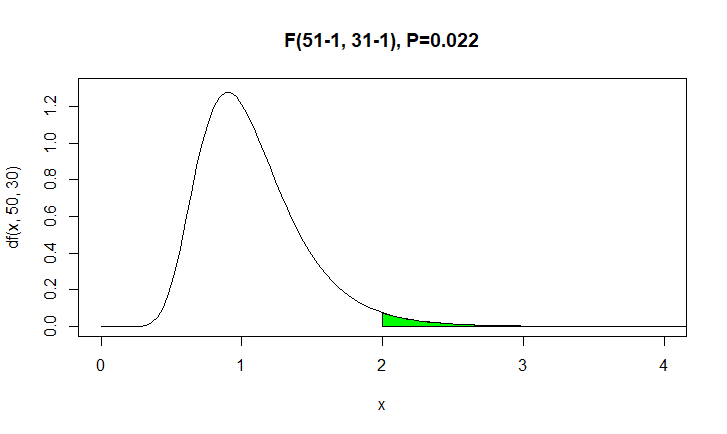
自由度 $(50, 30)$ のF分布の確率密度関数と,上側確率 $P(F > 2) = 0.022$ を示した図.
curve(
df(x, 50, 30),
type="l",
ylim=c(0, 1.3),
xlim=c(0, 4),
main="F(51-1, 31-1), P=0.022"
)
x <- qf(
pf(2, 50, 30, lower.tail=F),
50, 30,
lower.tail = F
)
x1 <- seq(x, 5,length=100)
y <- df(x1, 50, 30)
polygon(
c(x1, rev(x1)),
c(rep(0, length(x1)), rev(y)),
col="green"
)
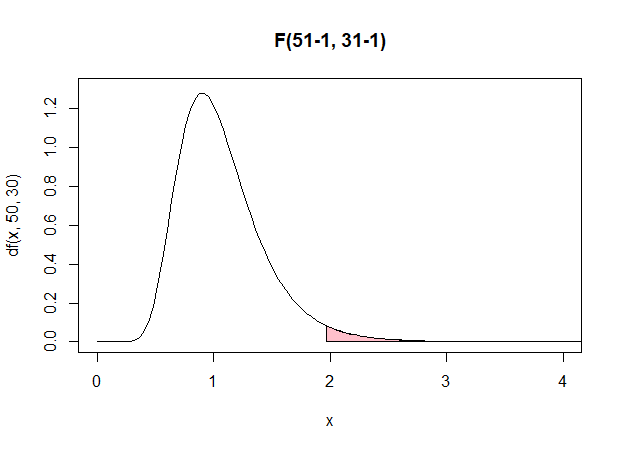
自由度 $(50, 30)$ のF分布における上側 $2.5\%$ の臨界領域を示した図.
curve(
df(x, 50, 30),
ylim=c(0,1.3), xlim=c(0,4),
type="l",
main="F(51-1, 31-1)"
)
x <- qf(0.025, 50, 30, lower.tail = F)
x1 <- seq(x, 5,length=100)
y <- df(x1, 50, 30)
polygon(
c(x1, rev(x1)),
c(rep(0, length(x1)), rev(y)),
col="pink"
)
curve(
df(x, 50, 30),
ylim=c(0, 1.3), xlim=c(0, 4),
type="l",
main="F(51-1, 31-1),P=0.025(ピンク)"
)
x <- qf(0.025, 50, 30, lower.tail=F)
x1 <- seq(x, 5,length=100)
y <- df(x1, 50, 30)
polygon(
c(x1, rev(x1)),
c(rep(0, length(x1)),
rev(y)),
col="pink"
)
x <- qf(pf(2, 50, 30, lower.tail=F), 50, 30, lower.tail=F)
x1 <- seq(x, 5,length=100)
y <- df(x1, 50, 30)
polygon(
c(x1, rev(x1)),
c(rep(0, length(x1)), rev(y)),
col="green"
)F(50,30):有意水準(ピンク)とp値(緑)の比較
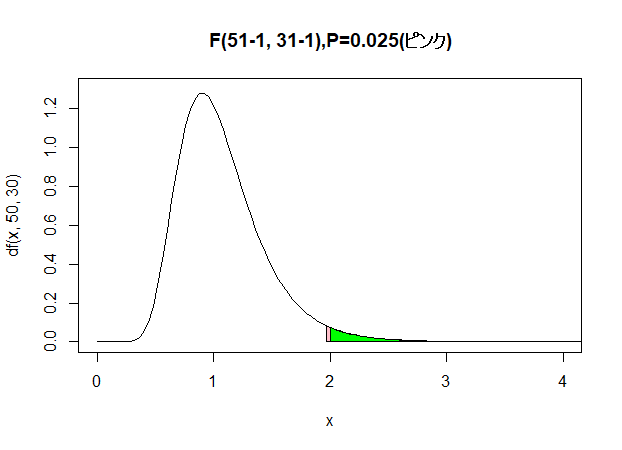
自由度 $(50, 30)$ のF分布において,ピンク色の領域は有意水準 $0.025$ に対応する棄却域を表し,緑色の領域は検定統計量 $F = 2$ に対応する上側確率(p値)を表す.このとき,緑色の領域(p値)はピンク色の領域(有意水準)より小さいため,
が成り立ち,帰無仮説は棄却される.
上側確率が $\alpha$ となる点(上側 $\alpha$ パーセント点)を $F_\alpha(n_1 – 1, n_2 – 1)$ と表す.例えば,$F_{0.025}(50, 30)$ は次のRコードで求めることができる:
qf(0.025, 50, 30, lower.tail = F)> qf(0.025, 50, 30, lower.tail = F)
[1] 1.968061