

分散分析で使用する用語の定義
| 用語 | 定義 |
| 観測値 | 各観測単位(被験者など)から得られる個々のデータを指し,測定値・計測値・評価尺度のスコアなどを含む. |
| 要因(factor) | 観測値に影響を与えると考えられるカテゴリカルな説明変数. |
| 水準(群) | 因子(分析で用いるカテゴリカル変数)が取りうるカテゴリー(例:運動療法1,運動療法2,運動療法3) |
| カテゴリカル変数 | 質的データ全体の総称(名義尺度および順序尺度を含む) |
| カテゴリー | カテゴリカル変数が取りうる値(例:男性,女性) |
| 因子型変数(factor) | カテゴリカル変数を表現するためのデータ型であり,その値であるカテゴリーは「水準(levels)」として扱われる.さらに,これらの水準の中から一つを基準水準(reference level)として設定することができ,回帰分析などにおいて他の水準との比較の基準として用いられる. |
※水準はカテゴリーと同じ内容を指すが,主に分散分析などのモデルの文脈で用いられる用語である.
データの準備と要約
例題
歩行が自立している高齢者を対象に、バランストレーニングの効果を検証するため、30名について床反力計を用いて足圧中心(COP)の総軌跡長を30秒間測定した。対象者は65–70歳、70–75歳、75–80歳の各年齢群にそれぞれ10名ずつ割り付けられている。以下のサンプルデータを用いて、年齢群間で差があるかどうかを有意水準5%で検定してみよう。
ID <- 1:30
cop <- c(1129,1009,1289,1052,995,1288,985,1095,977,1101,
1159,998,1302,1225,1203,1305,1155,1225,1085,1102,
1301,1240,1458,1320,1222,1420,1369,1330,1365,1235)
age <- c(rep("65–70", 10),
rep("70–75", 10),
rep("75–80", 10))
data <- data.frame(ID, cop, age)使用するパッケージ
library(tidyverse)
library(multcomp)サンプルは縦のデータセットです
View(data)
IDとageはカテゴリカル変数として扱い、factor()関数を用いて因子型変数に変換することで、その値であるカテゴリーは「水準(levels)」として定義される。
factor()関数を用いて因子型変数に変換して、水準(level)を確認
data <- data %>% mutate(
ID = factor(ID),
age = factor(age)
)
levels(data$age)> levels(data$age)
[1] "65–70" "70–75" "75–80"ダミー変数を作成する際のコントラストを確認するには contrasts() 関数を用いる。Rのデフォルトでは、すべての値が0となる水準がreference levelとなり、他の水準はそれとの比較として表現される。以下の例では、”65–70“がreference levelとなる。
contrasts(data$age)> contrasts(data$age)
70–75 75–80
65–70 0 0
70–75 1 0
75–80 0 1記述統計
データを散布図(ジッター付き散布図)にして視覚化する
p <- ggplot(data, aes(x = age, y = cop, color = age)) +
geom_jitter(width = 0.05, size = 3, alpha = 0.6) +
labs(x = "Age", y = "COP", title = "Data Distribution by Age Group") +
theme_minimal()
print(p)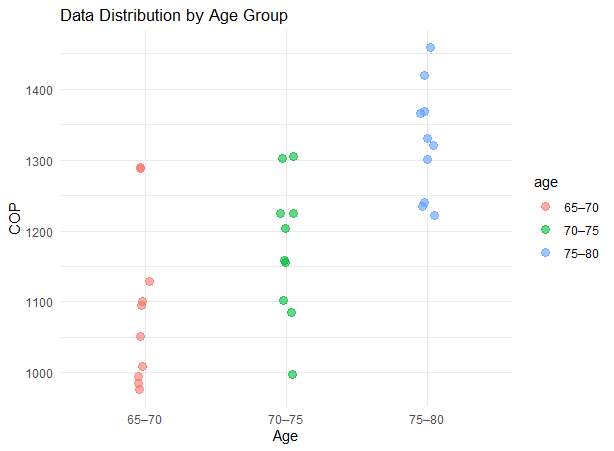
各水準ごとに、平均値、標準偏差、最小値、最大値および第1四分位数・中央値・第3四分位数を算出し、小数点第1位に丸める
result <- aggregate(
cop ~ age, data = data,
FUN = function(x) {
c(
mean = round(mean(x, na.rm = TRUE), 1),
sd = round(sd(x, na.rm = TRUE), 1),
min = round(min(x, na.rm = TRUE), 1),
Q1 = round(quantile(x, 0.25, na.rm = TRUE), 1),
median = round(quantile(x, 0.5, na.rm = TRUE), 1),
Q3 = round(quantile(x, 0.75, na.rm = TRUE), 1),
max = round(max(x, na.rm = TRUE), 1)
)
}
)
print(result)> print(result)
age cop.mean cop.sd cop.min cop.Q1.25% cop.median.50% cop.Q3.75% cop.max
1 65–70 1092.0 116.1 977.0 998.5 1073.5 1122.0 1289.0
2 70–75 1175.9 96.7 998.0 1115.2 1181.0 1225.0 1305.0
3 75–80 1326.0 79.4 1222.0 1255.2 1325.0 1368.0 1458.0回帰分析と分散分析
回帰分析
分散分析は一見すると「群間の平均値の差を検定する方法」であるが、実際には線形回帰モデルとして統一的に扱うことができる。モデルの推定には最小二乗法が用いられ(回帰分析)、その結果得られる残差を分解して検定が行われる(分散分析)。そのため、分散分析を行う際には、まず単回帰モデルとして定式化する。
#ageは名義変数
fit <- lm(cop~age, data=data)
summary(fit)Rで単回帰分析(線形モデル)を実行する際の基本的なプログラムを示す。ここでは、目的変数を cop、説明変数を age とする。age がカテゴリ変数の場合、Rは内部で自動的にダミー変数を生成して解析を行う。このときの符号化(コントラスト)の方法は、contrasts() 関数を用いて確認することができる。
Call:
lm(formula = cop ~ age, data = data)
Residuals:
Min 1Q Median 3Q Max
-177.90 -85.25 -1.50 47.58 197.00
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1092.00 31.17 35.037 < 2e-16 ***
age70–75 83.90 44.08 1.903 0.0677 .
age75–80 234.00 44.08 5.309 1.33e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 98.56 on 27 degrees of freedom
Multiple R-squared: 0.5173, Adjusted R-squared: 0.4816
F-statistic: 14.47 on 2 and 27 DF, p-value: 5.365e-05この結果から、回帰分析と分散分析の両方の観点からデータを解釈することができる。
回帰分析結果の解釈
reference level である age 65–70 の平均は 1092(切片)である。次に、age 70–75 の平均は 1092 + 83.9 = 1175.9 である。同様に、age 75–80 の平均は 1092 + 234 = 1326 である。これより、年齢群が高くなるにつれて平均値が増加する傾向が示される。
分散分析結果の解釈
出力の最下段に示されている F 統計量は、分散分析の結果に対応するものである。F検定の p値が 0.05 未満(p = 5.365 × 10⁻⁵)であることから、「すべての群の平均が等しい」という帰無仮説は棄却され、少なくとも1つの群間に有意差が存在すると結論づけられる。
分散分析表
回帰分析の結果をanova()関数に渡すことで分散分析表が出力される
anova(fit)> anova(fit)
Analysis of Variance Table
Response: data
Df Sum Sq Mean Sq F value Pr(>F)
age 2 281084 140542 14.468 5.365e-05 ***
Residuals 27 262275 9714 分散分析表
| 要因 | 自由度 (Df) | 平方和 (Sum Sq) | 平均平方 (Mean Sq) | F値 (F value) | p値 (Pr(>F)) |
|---|---|---|---|---|---|
| age | 2 | 281084 | 140542 | 14.47 | 5.365×10⁻⁵ |
| Residuals | 27 | 262275 | 9714 | — | — |
本結果は、回帰分析として lm(cop ~ age, data = data) を適用した後に、Rの anova() 関数を用いて分散分析表を算出したものである。anova(fit) によって得られる分散分析表は、この回帰モデルにおける変動の分解、すなわち全変動が説明変数(age)による変動(群間変動)と残差による変動(群内変動)にどのように分割されるかを示している。
この結果において、age に対応する平方和およびF値は、年齢群間の平均値の差に基づく変動(群間変動)を表している。一方、Residuals は各群内のばらつき(群内変動)を表している。F値は、群間変動を群内変動で割ったものであり、この値が大きいほど群間差が相対的に大きいことを意味する。
本結果では、F値に対応する p値が有意水準0.05未満であるため、年齢群によって cop の平均値に有意な差が存在すると結論づけられる。なお、一元配置分散分析と回帰分析(ダミー変数を用いたモデル)は統計的に等価であるため、このように回帰分析を介して anova() を適用して得られる分散分析表は、通常の一元配置分散分析と同一の内容を示すものである。