

分散分析表の理解
分散分析表(再掲)
| 要因 | 自由度 (Df) | 平方和 (Sum Sq) | 平均平方 (Mean Sq) | F値 (F value) | p値 (Pr(>F)) |
|---|---|---|---|---|---|
| age | 2 | 281084 | 140542 | 14.47 | 5.365×10⁻⁵ |
| Residuals | 27 | 262275 | 9714 | — | — |
平方和(sum of squares)は統計学における基本的な概念であり、ある基準値からの偏差の二乗を合計した量である。この基準値は文脈に応じて異なるが、例えば総平方和は平均からの偏差の二乗和として定義される。平均平方は、平方和を対応する自由度で割った値である。
テキストによって様々な記号や名称で表記されるが、本記事では以下の用語を用いる。
・全体平方和(total sum of squares)
・群間平方和(between-group sum of squares)
各群の平均と全体平均の差の二乗に、各群のデータ数 $n_i$ を掛けた量の総和である。
・群内平方和(within-group sum of squares;分散分析では残差平方和に対応)
各データとその属する群の平均との差の二乗の総和である。
散布図に全体平均と各群の平均を挿入する
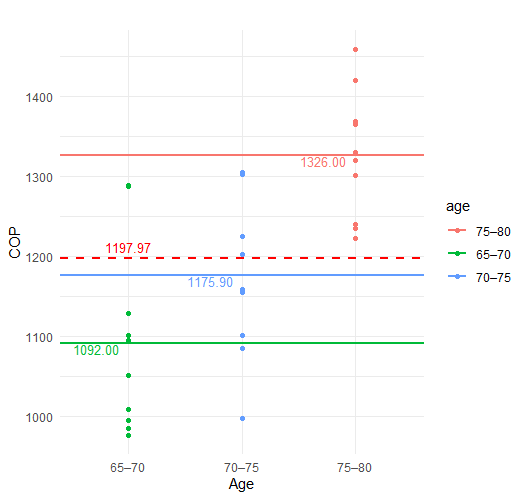
Rのコード
overall_mean <- mean(data$cop, na.rm = TRUE)
group_means <- data %>%
group_by(age) %>%
summarise(mean_value = mean(cop, na.rm = TRUE))
p <- ggplot(data, aes(x = factor(age, levels = c("65–70", "70–75", "75–80")),
y = cop,
color = age)) + # ← 追加
geom_point() +
# 全体平均(赤)
geom_hline(yintercept = overall_mean, color = "red", linetype = "dashed", linewidth = 1) +
annotate("text", x = 1, y = overall_mean, label = sprintf("%.2f", overall_mean),
hjust = 0.5, vjust = -0.5, color = "red", size = 3.5) +
# 群ごとの平均(色をageに対応させる)
geom_hline(data = group_means,
aes(yintercept = mean_value, color = age), size = 1) +
geom_text(data = group_means,
aes(x = age, y = mean_value, label = sprintf("%.2f", mean_value), color = age),
hjust = 1.2, vjust = 1, size = 3.5,
show.legend = FALSE) +
labs(x = "Age", y = "COP", title = "") +
theme_minimal()
print(p)
年齢を基準に、65〜70歳をA群、70〜75歳をB群、75〜80歳をC群とする。A群、B群、C群は互いに独立したサンプルからなるなるという点が重要である。群を識別する指標として $i$ を用い、 \(i=1,\, 2,\, 3\) とし、\(i=1\)(A群)、\(i=2\)(B群)、\(i=3\)(C群)と対応づける。
各群における観測値の番号を $j$ とすると,
\(j=1,\cdots,n_i\) (\(n_1=10, \, n_2=10, \, n_3=10\))
と表す。
各データは、\(y_{ij}\) で表され、これは「第 $i$ 群における第 $j$ 番目の観測値」を意味する。例えば $y_{27}$ は、第2群(B群)における7番目のデータである。
各群の平均は、$\hat{y}_i$ と表し,全体の平均は $\bar{y}$ とする。
本データでは $\bar{y}=1197.967$ である。
mean(data$cop)> mean(data$cop)
[1] 1197.967群の偏差と群内の偏差を以下に示す
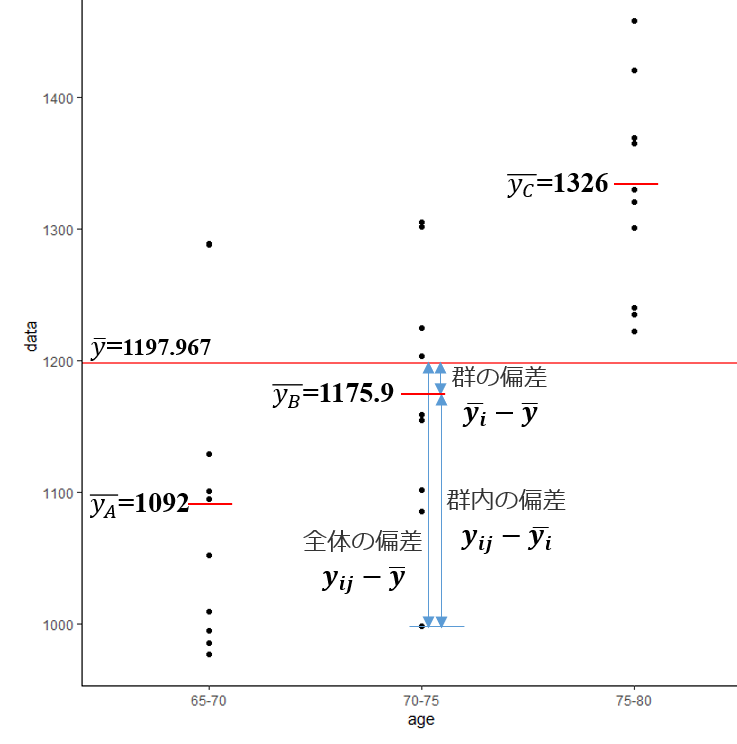
群平方和では、各群について1つの偏差(群平均と全体平均の差)を考える。この偏差は群内のすべての観測値で共通であるため、各群の群平方和はその偏差の二乗に標本サイズを掛けた形で表される。
例えば、群間平方和の中のA群の寄与は、
と表される。
同様にして、全体の群間平方和は
と表される。
一般には、これを次のようにまとめて書く:
全体平方和は
で定義される。(自由度:$n−1=29$)
群間平方和は、各群における偏差が $(\bar{y}_i – \bar{y})$ 群内で一定であることから、
と表される。(自由度:$群の数-1=2$)
群内平方和(残差平方和)は
である。(自由度:$n-群の数=27$)
分散分析では、群間平方和と群内平方和を用いて検定を行う。分散分析表においては、通常,全体平方和を直接用いる場面は多くない。
しかしながら、
が成り立つことから(以下で証明)、各平方和を自由度で割った平均平方の比を用いて検定統計量を構成し、群間差の有意性を評価する。したがって、理論的な関係を明示する目的で,全体平方和を改めて記載する場合もある。
平方和の分解
全体平方和は、群間平方和と群内平方和に分解できる
これを証明する。
ここで
を群の効果、
を残差とする。
一方、標本データに対しては、次の恒等式が成り立つ:
この式は、全体平均からの偏差が群間と群内に分解されることを示している。分散分析では、統計モデルを仮定することにより、この分解に対応した平方和に確率的な意味が与えられ、F検定が可能となる。
両辺の二乗和をとる
右辺を展開すると、
よって、
ここで、
が成り立つため、
より交差項は消える。したがって、
すなわち、
となることが示された。
分散分析の検定方法
一元配置分散分析では、次のような統計モデルを仮定する
$\mu$:母集団の全体平均(未知のパラメータ)
$α_i$:群効果
$e_{ij}$:誤差
帰無仮説は
である($\mu_i=\mu+\alpha_i$)。
平方和から平均平方を算出し、群間平均平方と群内平均平方の比がF分布に従うことを利用して検定を行う。
検定統計量($F$値)は、
である(再掲)。
このとき、
に従う。
本例では、
である。したがって、
となる場合には、帰無仮説を棄却する。
本例の$F$値は、分散分析表より
となる。
$F_{0.95}(2, 27)$ (F分布の95%分位点) を求める。
# F分布の上側5%点(95%分位点)
qf(0.95, 2, 27)> qf(0.95, 2, 27)
[1] 3.354131p値は、観測されたF統計量(14.47)に対するF分布の上側確率として定義される。
# 観測されたF値に対する上側確率(p値)
pf(14.47, 2, 27, lower.tail = FALSE)> pf(14.47, 2, 27, lower.tail = FALSE)
[1] 5.359911e-05
結果
F値ベースの書き方
有意水準5%において検定を行った結果、
となるため、帰無仮説は棄却された。したがって、群間に有意な差が認められる。
p値ベースの書き方
有意水準5%において検定を行った結果、p値は0.05未満であったため、帰無仮説は棄却された。したがって、群間に有意な差が認められる。
群間平均平方和の確認
確認のため、サンプルデータから群間平均平方を計算する。
gun <- (
(mean(data[data$age == "65–70", "cop"]) - mean(data$cop))^2 *
nrow(data[data$age == "65–70", ]) +
(mean(data[data$age == "70–75", "cop"]) - mean(data$cop))^2 *
nrow(data[data$age == "70–75", ]) +
(mean(data[data$age == "75–80", "cop"]) - mean(data$cop))^2 *
nrow(data[data$age == "75–80", ])
) / (3 - 1)
print(gun)> print(gun)
[1] 140542残差平均平方和の確認
確認のため、サンプルデータから群間平均平方を計算する。
zan <- (
sum((data[data$age=="65–70", "cop"] - mean(data[data$age=="65–70", "cop"]))^2) +
sum((data[data$age=="70–75", "cop"] - mean(data[data$age=="70–75", "cop"]))^2) +
sum((data[data$age=="75–80", "cop"] - mean(data[data$age=="75–80", "cop"]))^2)
) / 27
print(zan)> print(zan)
[1] 9713.885> qf(0.95, 2, 27)
[1] 3.354131本記事の作成にあたり、AIを用いて文章表現および構成の補助を行っています。掲載内容については管理者が確認・修正を行ったうえで公開しており、その内容に関する責任は管理者にあります。