

分散分析で使用する用語の定義
本サイトで使用する用語について
| 観測値 | 被験者から得られる個々のデータを指す.測定値,計測値,評価尺度のスコアなどが含まれる. |
| カテゴリカル変数 | 質的データ全体の総称(名義尺度および順序尺度を含む). |
| 連続変数 | 連続的な値を取る量的データであり,間隔尺度または比率尺度として測定される数値データ. |
| カテゴリー | カテゴリカル変数が取りうる値(例:男性,女性). |
| 因子(factor) | 要因と同義.観測値に影響を与えると考えられるカテゴリカル変数. |
| 水準(群) | 因子が取りうる個々のカテゴリー(例:運動療法1,運動療法2,運動療法3). |
| 因子型変数(factor) | カテゴリカル変数を表現するデータ型であり,その値は水準(levels)として扱われる.さらに,基準水準(reference level)を設定し,他の水準との比較の基準として用いることができる. |
繰り返しあり,繰り返しなし,反復測定
|
繰り返しあり with replication |
1セルに複数の対象者(患者・被験者)から得られた観測値が存在する場合 |
|
繰り返しなし without replication |
1セルに1つの観測値しか存在しない場合 |
|
反復測定 repeated measurement, repeated measures |
同じ対象者(患者・被験者)から複数回観測値を得ること.例えば,同一被験者を1週目,2週目,3週目など複数の時点で測定する場合が該当する. |
※ with/without replication は「セル内のデータ数」の違いを指し,repeated measures は「同一被験者に複数条件を割り付ける設計」を指す.両者は概念的に別である.
一元配置分散分析
一元配置分散分析(繰り返しあり)
one-way analysis of variance: one-way ANOVA
以下の例では,因子は運動療法であり,その水準は運動療法1~3である.観測値は歩行速度である.各被験者は1つの水準のみに割り付けられており,他の水準には割り付けられていない.また,各水準には5名の被験者が含まれるため,各セルには5つの観測値が存在する(繰り返しあり).
subject:被験者
therapy:運動療法(水準)
speed:歩行速度
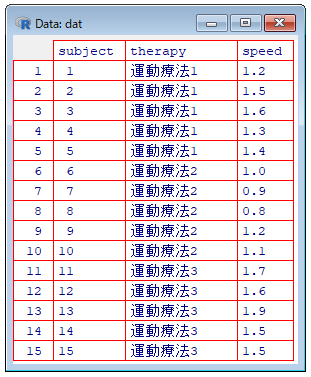
Rのコード
dat <- data.frame(
subject = 1:15,
therapy = c(rep("運動療法1",5),
rep("運動療法2",5),
rep("運動療法3",5)),
speed = c(1.2, 1.5, 1.6, 1.3, 1.4,
1.0, 0.9, 0.8, 1.2, 1.1,
1.7, 1.6, 1.9, 1.5, 1.5)
)
View(dat)
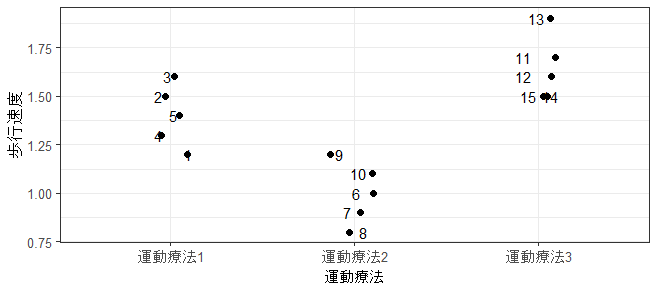
Rのコード
dat <- data.frame(
subject = 1:15,
therapy = c(rep("運動療法1",5),
rep("運動療法2",5),
rep("運動療法3",5)),
speed = c(1.2, 1.5, 1.6, 1.3, 1.4,
1.0, 0.9, 0.8, 1.2, 1.1,
1.7, 1.6, 1.9, 1.5, 1.5)
)
library(ggplot2)
ggplot(dat, aes(x = therapy, y = speed)) +
geom_point(size = 2,
position = position_jitter(width = 0.15, height = 0)) +
geom_text(aes(label = subject),
position = position_jitter(width = 0.1, height = 0),
size = 4) +
labs(
x = "運動療法",
y = "歩行速度"
) +
theme_bw(base_size = 12)
一元配置分散分析は,「1つの因子によって分けられた複数水準の平均値に差があるか」を検証する方法である.ここで扱う因子は1つのみであり,各対象はいずれか1つの水準に属する.この方法では「各水準による違い」に注目し,個人差や測定環境などに由来するばらつきはすべて誤差として扱う.そのため,被験者間の個体差が大きい場合には誤差分散が増大し,水準間の差を検出しにくくなることがある.
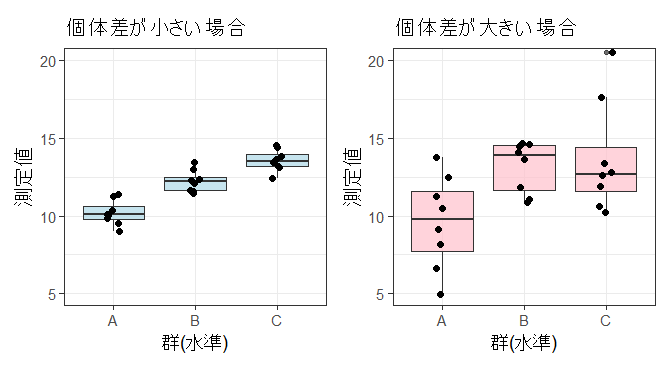
Rのコード
ylim <- c(5, 20)
p1 <- ggplot(dat_small,
aes(x = group, y = y)) +
geom_boxplot(fill = "lightblue", alpha = 0.7) +
geom_jitter(width = 0.08, size = 2) +
coord_cartesian(ylim = ylim) +
labs(title = "個体差が小さい場合",
x = "群(水準)",
y = "測定値") +
theme_bw(base_size = 14)
p2 <- ggplot(dat_large,
aes(x = group, y = y)) +
geom_boxplot(fill = "pink", alpha = 0.7) +
geom_jitter(width = 0.08, size = 2) +
coord_cartesian(ylim = ylim) +
labs(title = "個体差が大きい場合",
x = "群(水準)",
y = "測定値") +
theme_bw(base_size = 14)
p1 + p2

一元配置分散分析(繰り返しなし)
繰り返しなしの場合,データは各水準に1点ずつ対応するため視覚的には折れ線グラフのようになるが,水準内変動が存在しないため分散分析の前提が満たされない.
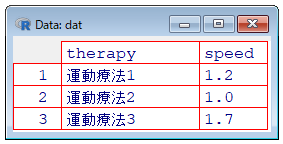
Rのコード
# データ作成(without replication)
dat <- data.frame(
therapy = c("運動療法1", "運動療法2", "運動療法3"),
speed = c(1.2, 1.0, 1.7)
)
View(dat)
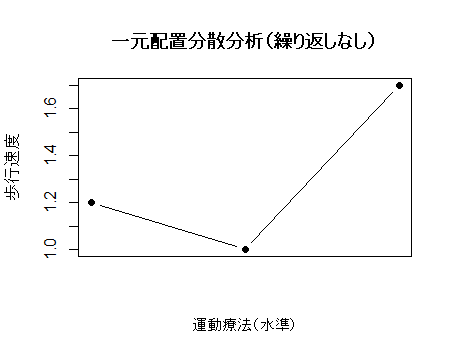
Rのコード
dat <- data.frame(
therapy = c("運動療法1", "運動療法2", "運動療法3"),
speed = c(1.2, 1.0, 1.7)
)
# グラフ
x <- 1:length(dat$therapy)
plot(x, dat$speed,
type = "b",
pch = 16,
xaxt = "n", # x軸を自分で設定
xlab = "運動療法(水準)",
ylab = "歩行速度",
main = "一元配置分散分析(繰り返しなし)")
axis(1, at = x, labels = dat$therapy)
一元配置反復測定分散分析
one-way repeated-measures ANOVA
一元配置反復測定分散分析(one-way repeated-measures ANOVA)は,被験者をブロックとするランダム化ブロックデザイン(randomized block design: RBD)と同型の分散分析表をもつ.すなわち,被験者間変動をブロック効果として分離することで,処理(水準)効果の検出力を高めることができる.しかし,反復測定データでは同一被験者から複数の観測値が得られるため,各観測値は独立ではなく,被験者内相関が存在する.この点が通常のランダム化ブロックデザインと異なる.そのため,反復測定データの解析では被験者内相関を考慮した統計モデルが必要となり,このような手法を反復測定分散分析(repeated-measures ANOVA)という.
subject:被験者
time:測定時期
speed:歩行速度
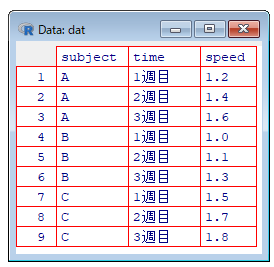
Rのコード
dat <- data.frame(
subject = rep(c("A", "B", "C"), each = 3),
time = rep(c("1週目", "2週目", "3週目"), times = 3),
speed = c(
1.2, 1.4, 1.6, # 被験者A
1.0, 1.1, 1.3, # 被験者B
1.5, 1.7, 1.8 # 被験者C
)
)
View(dat)
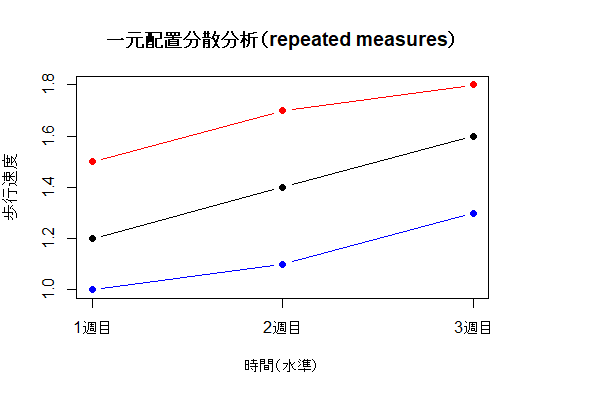
Rのコード
dat <- data.frame(
subject = rep(c("A", "B", "C"), each = 3),
time = rep(c("1週目", "2週目", "3週目"), times = 3),
speed = c(
1.2, 1.4, 1.6, # 被験者A
1.0, 1.1, 1.3, # 被験者B
1.5, 1.7, 1.8 # 被験者C
)
)
# 因子型に変換(順序を保つ)
dat$time <- factor(dat$time, levels = c("1週目", "2週目", "3週目"))
# x軸(数値化)
x <- as.numeric(dat$time)
# 余白を右に広げる
par(mar = c(5, 4, 4, 6)) # 右側を広く
# 空のプロット
plot(range(x), range(dat$speed),
type = "n",
xaxt = "n",
xlab = "時間(水準)",
ylab = "歩行速度",
main = "一元配置分散分析(repeated measures)")
axis(1, at = 1:3, labels = levels(dat$time))
# 線の描画
subjects <- unique(dat$subject)
colors <- c("black", "blue", "red")
for (i in seq_along(subjects)) {
d <- subset(dat, subject == subjects[i])
lines(1:3, d$speed, type = "b", pch = 16, col = colors[i])
}
# 凡例(右外)
legend("topright",
inset = c(-0.25, 0), # ← 右に押し出す
legend = subjects,
col = colors,
lty = 1,
pch = 16,
xpd = TRUE) # 描画領域外を許可
反復測定分散分析では,同一被験者が複数の条件に割り付けられる.例えば,同じ被験者が1週目,2週目,3週目のすべてで測定される場合である.このように,同一被験者のデータが複数条件に対応するため,測定値間には被験者内相関が生じる.この例では,1週目,2週目,3週目の3時点で歩行速度を測定し,時間の経過に伴って平均値が変化したかを検討している.
反復測定分散分析では,被験者内相関を考慮した統計モデルを用いることで,各被験者を自らの対照として比較することができる.その結果,被験者ごとの個体差をモデル内で分離して扱うことが可能となり,通常の一元配置分散分析と比較して誤差分散を小さくできる場合が多い.
したがって,個体差の影響を抑えながら,時間経過による変化をより高い精度で評価できることが,反復測定分散分析の特徴である.
この例題に一元配置分散分析(with replication)を用いると,同一被験者からの測定であるにもかかわらず独立な観測値として扱われる.その結果,被験者ごとの個体差(体力や年齢など)も誤差分散として扱われる.
