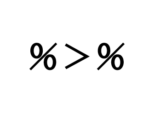パッケージ
パケージのインストールで R を挫折する人もおられますので解説します。Rのパッケージは、関数やデータセットをまとめたもので、世界中の研究者から無償で提供されています。Rには「base」といったデフォルトで最初からインストールされているパッケージもありますが、追加のパッケージはCRAN(Comprehensive R Archive Network)を通してダウンロードすることができます。CRANはR言語のパッケージ、ソフトウェア、そして関連するドキュメントが集められ、配布されるネットワークで、全世界にミラーサイトが存在します。
パッケージの保存場所とパス指定
パッケージがどこに保存されるか確認してみます。Rを使用していくと、保存場所が数カ所存在する場合もあります。
.libPaths()
パッケージをダウンロードする前に、.libPaths()関数でパッケージの保管場所を指定されることを推奨します。デスクトップに専用のフォルダ(例:Rpackages)を作成しても構いません…フォルダ名は何でも大丈夫です。Rに標準装備されているパッケージ(base)以外のパッケージを保管する場所になります。Rを更新した場合でも、同じ場所に保管しておくことで,これまでインストールしたパッケージを継続して使用することができます。
例として、デスクトップにRpackagesというフォルダを作成して,パッケージを保管するフォルダに指定します。
# The package folder created on the desktop
.libPaths("C:/Users/your PC name/Desktop/Rpackages")
# for MAC
.libPaths(new = "/your/custom/path")R3.2.0より以前のバージョンでは スラッシュの代わりにバックスラッシュを2つ(\\\\)書かなければなりません。
これでパッケージの保管場所が指定できました
その後は、パッケージをダウンロードしたら、同じ場所に保管してくれます
僕の保管フォルダ(Rpackages)の中を見てみます。いろいろなパッケージがあります。一度ダウンロードしたら次回からはダウンロードが不要です。
パッケージのダウンロード
それでは実際にパッケージをダウンロードしてみましょう。試しにdplyrというパッケージをCRANからダウンロードしてみます(dplyrを利用することで一覧表の操作が楽になります)。インストールは,install.packages()関数を使用します。下記のコードをペーストしてEnterをクリックするとダウンロードが始まります。
install.packages("dplyr")では、実際にやってみましょう。CRANはJapanを選択してOKをクリックしてください。最後にどこにインストールされたか表示されます。他のパッケージもインストールしたらここに追加されることになります。私の場合は常にデスクトップに置いておきたいので、インストール場所をデスクトップに指定します。Rのバージョンを変更したときも常に同じ場所にパッケージを保管しておけばすぐに使えます。また、他のPCで作業する場合もパッケージだけ持ち出すことパッケージを使用することができます(もちろん再度ダインロードしても構いません)。
パッケージを起動する library()関数
パッケージを使う場合は、library()関数 を使用します。
library(dplyr)これでパッケージdplyrが使える状態になります。プログラムのなかで :: の記号がある場合は、「このパッケージを使用してます」という意味です(記号::は、使用しなくても構いません)。ダウンロードした、パッケージdplyrを使用してみます。データセット sample01 をdataに格納します(ファイルの読み込み)。
data <- read.csv("sample01.csv", header=T, fileEncoding = "UTF-8")
head(data)
ダウンロードしたパッケージdplyrをlibrary()関数で起動します。
library(dplyr)treatmentAとBのage、scoreの平均および標準偏差を一気に出力。group_by()で層別、summarise()で各層の要約を実行します。na.rm = TRUEは、欠損値を無視するための理論値です。.group = “drop” により、summarise()関数が保持しているグループ化を解除することができる。改めて、group_byで設定すれば問題はない。
data %>%
group_by(treatment) %>%
summarise(
age_mean = mean(age, na.rm = TRUE),
age_sd = sd(age, na.rm = TRUE),
score_mean = mean(score, na.rm = TRUE),
score_sd = sd(score, na.rm = TRUE),
.group = "drop"
)
階層的な構造(入れ子)になっている値の要約
各treatmentの男性、女性の人数を一気に出力。
data %>%
group_by(treatment, sex) %>%
summarise(
count = n() ,
.groups = "drop"
)