

$ICC(1,1):$は、一人の評価者が測定した値の信頼性や一貫性を評価します
$ICC(1,k):$は、一人の評価者が測定した値の平均値の信頼性や一貫性を評価します
$ICC(2, 1)$では、数名の評価者が測定した値の信頼性や一貫性を評価します
$ICC(2, k)$では、数名の評価者が測定した平均値の信頼性や一貫性を評価します
$ICC(3, 1)$では、評価者を固定した場合の測定値の信頼性や一貫性を評価します(評価者間のばらつきは考慮されません)
$ICC(3, k)$では、評価者を固定した場合の測定値の平均値の信頼性や一貫性を評価します(評価者間のばらつきは考慮されません)
下記の文献のICC(1, 1)、ICC(1, k)をRでやってみます.
Shrout PE, Fleiss JL. Intraclass correlations: uses in assessing rater reliability. Psychol Bull. 1979 Mar;86(2):420-8. doi: 10.1037//0033-2909.86.2.420.
サンプルはここからです、いつもお世話になっております

データの準備と要約
以下のファイルを読み込んでください(ファイルの読み込み方)
dat <- read.csv("ICC01.csv", header=T, fileEncoding = "UTF-8")
head(dat)評価者 1名、被験者患 10名、測定回数 3 回
> head(dat)
ID test1 test2 test3 mean
1 1 15 10 21 15.333
2 2 30 14 38 27.333
3 3 34 42 36 37.333
4 4 52 38 40 43.333
5 5 58 51 42 50.333
6 6 69 78 63 70.000ICC(1,1)、ICC(1,k)はともに同じファイルを使用します
ICC(1, 1)とICC(1, k)の答えです
ICC(1,1)≒0.942、95%信頼区間:0.848 0.984 ICC(1,3)≒0.980、95%信頼区間:0.943 0.995
Rを使いながら、この解がどのようにして導かれたのかを解説します
使用するパッケージ
library(irr)
library(tidyr)
library(ggplot2)縦のデータに変換
dat2 <- tidyr::gather(
dat[,-5],
key=PT,
value=data,
-ID)
head(dat2)> head(dat2)
ID PT data
1 1 test1 15
2 2 test1 30
3 3 test1 34
4 4 test1 52
5 5 test1 58
6 6 test1 69変数をfactorへ変換(ここを忘れたらグラフが変わります)
dat2$PT <- as.factor(dat2$PT)
levels(dat2$PT)
dat2$ID <- as.factor(dat2$ID)
levels(dat2$ID)> dat2$PT <- as.factor(dat2$PT)
> levels(dat2$PT)
[1] "test1" "test2" "test3"
> dat2$ID <- as.factor(dat2$ID)
> levels(dat2$ID)
[1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10"factor() 関数は名義変数をカテゴリカル変数(因子型変数)に変換し、データのカテゴリーは「水準」として定義されます。levels() 関数で表示されるカテゴリカル変数の水準のうち、最初に表示されるカテゴリーがデフォルトで基準カテゴリー(参照カテゴリー)となり、統計モデルでの比較の基点として機能します。relevel() 関数や factor() 関数の levels 引数を使用することで、レベルの順序を指定し、基準カテゴリーを変更することが可能です。
ICC(1, 1) 3回の計測結果が対象
1人の評価者が患者 ($n=10$) に対して検査を数回 ($k=3$)実施した時の信頼性を求めます。検査結果($test1, test2, test3$)の誤差が小さいと信頼性が高いと判断します。
グラフでデータ構造をイメージ
g1 <- ggplot2::ggplot(
dat2,
aes(x = PT, y = data)
)
g2 <- g1 + geom_jitter(
height=0, width =0.1, size = 3,
aes(colour = ID)
)
g2 + theme_test() + xlab("") +ylab("結果")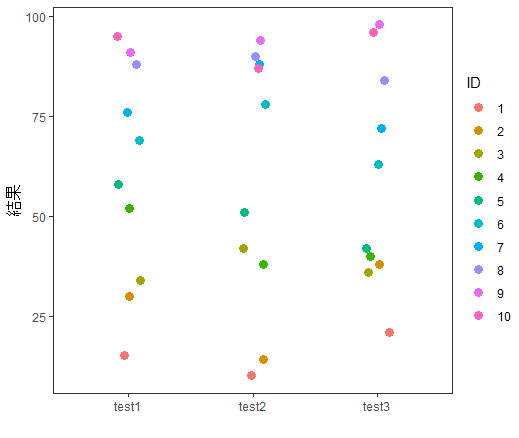
このように、IDをブロック因子とした二元配置分散分析(繰り返し測定なし)のグラフを描かれるかもしれません・・・。対応のある一元配置分散分析とも呼ばれています。でもIDを要因として考えて、以下ようなグラフをイメージしておくと理解しやすくなります。
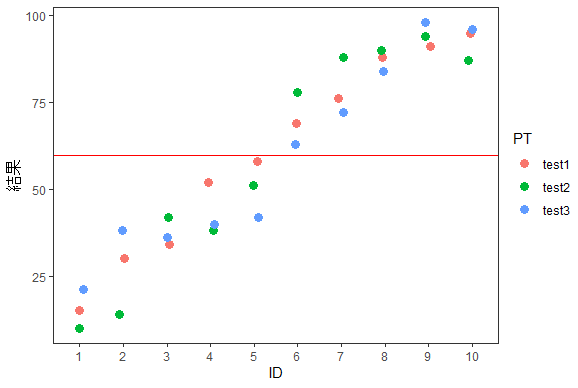
#グラフの描き方
g1 <- ggplot2::ggplot(
dat2,
aes(x = ID, y = data)
)
g2 <- g1 + geom_jitter(
height=0, width =0.1, size = 3,
aes(colour = PT)
)
m <- mean(dat2$data)
g2 + theme_test() +
xlab("ID") + ylab("結果") +
geom_hline(aes(yintercept = m),
color = "red"
)Rの関数でICCを求める
パッケージirrのicc関数には下記のような引数が用意されています

3回計測(oneway)の一貫性(consistency)をそれぞれのデータ(single)から評価します
irr::icc(
dat[,2:4],
model="oneway",
type="consistency",
unit="single"
)注意)横データを使っています
Single Score Intraclass Correlation
Model: oneway
Type : consistency
Subjects = 10
Raters = 3
ICC(1) = 0.942
F-Test, H0: r0 = 0 ; H1: r0 > 0
F(9,20) = 50.2 , p = 9.01e-12
95%-Confidence Interval for ICC Population Values:
0.848 < ICC < 0.984結果のみでよければ、ここまでです
ここからは、もう少し詳しく勉強しましょう