

*本サイトのサンプルデータは全て架空のものです
超幾何分布は、有限個の要素から成る母集団より無作為に抽出したサンプルにおいて、特定の属性を持つ要素が何個含まれているかを示す確率変数の分布です。例えば、赤玉と白玉が混在する袋から無作為に玉をいくつか取り出す場合、取り出された赤玉の数の確率を求めるのに適用できます。Fisherの正確確率検定やログランク検定などで利用されている確率分布です。
データの準備と要約
Fisherの正確確率検定で使用している以下の分割表(クロス表)をサンプルにします
仮想例題)29名(重度群15名、軽度群14名)の患者に対して治療Aを実施した。効果があったのは18例で、その中の重症群は12例であった。
この例をクロス表にすると以下のようになります
severity <- c(rep("severe", 12), rep("mild", 6), rep("severe", 3), rep("mild", 8))
severity <- factor(severity, levels=c("severe", "mild"))
levels(severity)
#[1] "severe" "mild"
effect <- c(rep("yes", 18), rep("no", 11))
effect <- factor(effect, levels=c("yes", "no"))
levels(effect)
#[1] "yes" "no"
tab <- xtabs( ~ severity + effect)
addmargins(tab)
障害レベル; severity(severe=重度, mild=軽度)
効果; effect(yes=あり, no=なし)
超幾何分布
上記の例を一般化します
対象者数: N 人
対象者の内訳:重度群 M 人、軽度群 N-M 人
全体の効果:治療Aの効果あり k 人
重度群の効果:重度群のなかで治療Aの効果があった人数 x 人
cross2 <- matrix(c(
"x", "k-x", "k",
"", "", "",
"M", "N-M", "N"),
ncol = 3)
colnames(cross2) <- c("yes", "no", "sum")
rownames(cross2) <- c("severe", "mild", "sum")
View(cross2)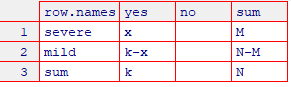
超幾何分布は、3つのパラメーター、N(全体の数)、M(特定の特徴を持つ要素の数)、k(抽出されるサンプルのサイズ)に基づきます。確率変数 X は、「k 回の抽出で得られた特定の特徴を持つ要素の数(x)」を表します。このような場合、X が従う分布を超幾何分布といいます。
M, N, k が分かると周辺和 がすべて固定され、さらに4つのセルのなかの1つ(x)を決めることで他のセルが全部決まります(自由度=1)。
超幾何分布の確率関数
超幾何分布の確率関数は、このような特定の条件下での組み合わせ (C=combination)の確率として表されます
確率関数: $P(X=x) = \dfrac{_{M}C_{x}\times_{N-M}C_{k-x}}{_NC_k}$
$P(X=x)=\dfrac{( M 人から x 人を選択)( N-M から k-x 人を選択)}{全体 N 人から k 人を選択}$
確率変数$X$が超幾何分布に従っている場合の $X$ の期待値 $E(X)$ と分散 $V(X)$
期待値:$E(X) = k\dfrac{M}{N}$
分散:$V(X) = k\dfrac{M(N-M)}{N^2}\dfrac{N-k}{N-1}$
Rのdhyper関数
治療Aを受けた29名の例は以下のようになります(再掲)
$P(X=12)=\dfrac{_{15}C_{12}\times_{14}C_{6}}{_{29}C_{18}}=0.03949341$
組み合わせの数を求めるRの関数 choose を使用して次のように書くことができます
choose(15, 12)*choose(14, 6)/choose(29, 18)
関数 dhyper を使用して、もっと簡単に書くことができます
P(X=x)= dhyper(x, m, n, k)
dhyper(x=12, m=15, n=14, k=18)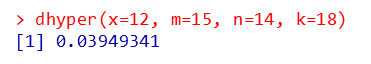
Rのdhyperは、通常の超幾何分布のパラメーター表記とは異なりますので注意が必要です
N = m+n
M = m
x = x
k = k
x : 赤玉が抽選される量子(quantiles)を表すベクトルです. 袋から置き換えなしで赤玉が引かれることを意味します。(非復元抽出法)
m : 袋の中の赤玉の総数
n : 袋の中の白玉の総数
k : 袋から取り出された玉の総数. この数は0からm+nまでの範囲でなければなりません. つまり、抽選される玉の数は袋の中の玉の総数を超えることはできません.
(R: The Hypergeometric Distribution を一部改変)
超幾何分布の確率関数グラフ
P(X)が従う分布を超幾何分布といいます。ここの例では重度群の人数は15名なので、X の範囲は 0~15 となります。どのような分布になるか見てみましょう。
library(ggplot2)
# データの生成
x <- 0:15
p <- dhyper(x, 15, 14, 18)
# データフレームの作成
df1 <- data.frame(x, p)
# ggplotを使ったグラフの描画
ggplot(df1, aes(x = x, y = p)) +
geom_bar(stat = "identity", fill = "skyblue", color = "black") +
theme_minimal() + # シンプルでモダンなテーマの適用
labs(x = "x", y = "Probability", title = "超幾何分布") +
geom_point(size = 3, color = "red") + # データポイントを強調
geom_line(aes(group = 1), color = "red") 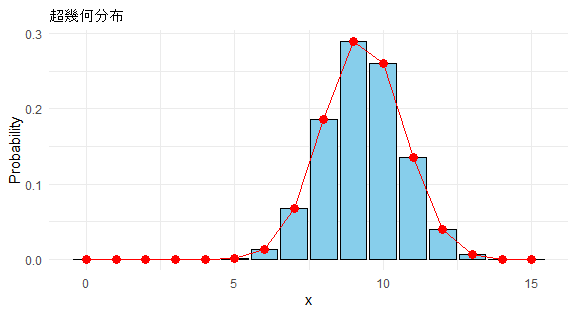
X が12、13、14、15 のときの確率を足せば片側検定のP値となります。
x が12以上になる確率が小さい値になれば、偶然に起こったことと言えなくなります。なので、効果の割合に差があると言えるのです。