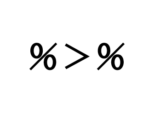パッケージを使う場合は、library()関数 を使用します。
R
library(dplyr)これでパッケージdplyrが使える状態になります。プログラムのなかで :: の記号がある場合は、「このパッケージを使用してます」という意味です(記号::は、使用しなくても構いません)。ダウンロードした、パッケージdplyrを使用してみます。データセット sample01 をdataに格納します(ファイルの読み込み)。
R
data <- read.csv("sample01.csv", header=T, fileEncoding = "UTF-8")
head(data)
ダウンロードしたパッケージdplyrをlibrary()関数で起動します。
R
library(dplyr)treatmentAとBのage、scoreの平均および標準偏差を一気に出力。group_by()で層別、summarise()で各層の要約を実行します。na.rm = TRUEは、欠損値を無視するための理論値です。.group = “drop” により、summarise()関数が保持しているグループ化を解除することができる。改めて、group_byで設定すれば問題はない。
R
data %>%
group_by(treatment) %>%
summarise(
age_mean = mean(age, na.rm = TRUE),
age_sd = sd(age, na.rm = TRUE),
score_mean = mean(score, na.rm = TRUE),
score_sd = sd(score, na.rm = TRUE),
.group = "drop"
)
階層的な構造(入れ子)になっている値の要約
各treatmentの男性、女性の人数を一気に出力。
R
data %>%
group_by(treatment, sex) %>%
summarise(
count = n() ,
.groups = "drop"
)