

例題 この研究には5施設(施設ID=A, B, C, D, E)の回復期病棟が参加した。乱塊法(Random Block method)に従い、理学療法を1週間受けている患者1名、2週間受けけている患者1名、3週間受けている患者1名を5施設からそれぞれランダムに抽出し(n=15)、TUG(time up & go test)を測定して各期間の差を検証した(患者情報は除外)。
僕が作った架空のデータで練習しましょう。結果についてはご意見があると思いますが、統計学の練習のためのサンプルですのでご了承ください。
データの準備と要約
使用するパッケージ(ダウンロードの方法)
R
library(tidyr)
library(ggplot2)以下のファイルを読み込んでください(ファイルの読み込み方)
R
dat <- read.csv("anova02.csv", header=T, fileEncoding = "UTF-8")データの確認
R
head(dat)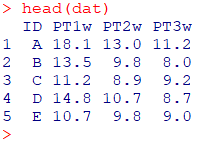
R
rowMeans(dat[,-1]) #行平均(各患者の平均)
colMeans(dat[,-1]) #列平均(各期間での平均)
PT実施期間を要因A、施設を要因Bとします

- 要因Aに着目するので、要因Bの施設水準はブロック因子となります
- 1~3週間のことを要因Aの水準、施設A~Dのことを要因Bの水準と言うこともあります
- 繰り返し測定なし=1つの水準に含まれるデータが1つ
縦のデータセットに変換(縦持ち)
R
dat2 <- tidyr::gather(
dat,
key=point,
value=data,
-ID)
head(dat2)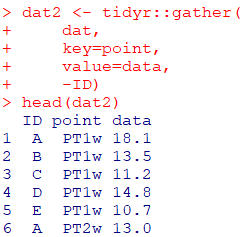
全体の平均
R
mean(dat2$data)
名義変数はfactorに変更
R
str(dat2)
pointはcharacter変数ですが、解析する場合にはレベルが付与されるfactor変数に変換しておきましょう(character、factorはともに名義変数です)
R
dat2$ID <- as.factor(dat2$ID)
dat2$point <- as.factor(dat2$point)
str(dat2)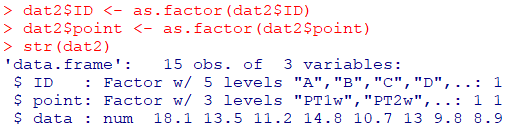
- IDとpointはFactor変数になり、レベルも付いてます
- 基準レベルは、ID=1、point=PT1wとなります(先頭の文字)
グラフ
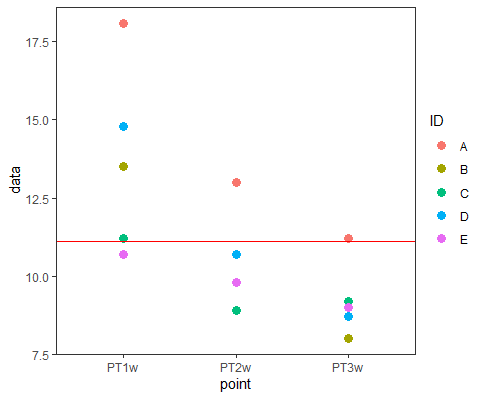
R
#グラフの描き方
g1 <- ggplot2::ggplot(
dat2,
aes(x = point, y = data)
)
g2 <- g1 + geom_point(
aes(x = point, y = data, color=ID),
size = 3) +
theme_test()
y <- mean(dat2$data)
(g3 <- g2 + geom_hline(
aes(
yintercept = y
),
color = "red"
))