

ロジスティック回帰 (1)の続きです。例題はロジスティック回帰 (1)と同じですが、データセットの構造が異なります。例題の内容や結果については色々とご意見があると思いますが、統計学の練習のためのサンプルですのでご了承ください。

例題 リハビリを受けている入院中の患者に対してリハビリに関する満足度調査を実施した。1週間に割り当てられた単位数をもとにランダムにインタビューした。「満足」と回答する割合と1週間のリハビリ単位数には関係があるのでしょうか?
データの準備と要約
データセット log01 と log02 をダウンロードします(ファイルの読み込み方)
集計データ
R
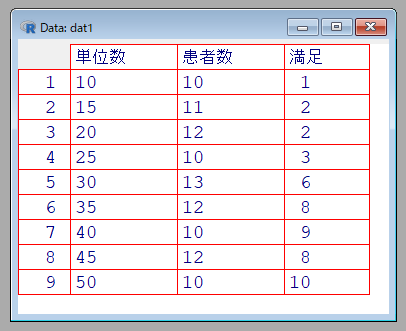
dat1 <- read.csv("log01.csv", header=T, fileEncoding = "UTF-8")dat1の確認
R
View(dat1)単位数=1週間のリハ単位数
患者数=各単位数に該当する患者数
満足=「満足」と回答した患者数
個別データ
R
dat2 <- read.csv("log02.csv", header=T, fileEncoding = "UTF-8")dat2の確認
R
dim(dat2)> dim(dat2)
[1] 100 2100人分あるので20人分のみを表示してみます
R
#20行のみ表示
View(dat2[0:20,])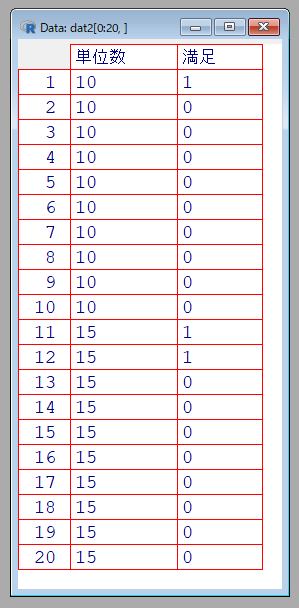
ロジスティック回帰
それぞれのセットでロジスティック回帰を実行してみます
目的変数の設定が異なるので注意してください
集計データを使用したロジスティック回帰
R
fit1 <- glm(
cbind(満足, 患者数-満足) ~ 単位数,
family=binomial,
data=dat1
)
summary(fit1)Call:
glm(formula = cbind(満足, 患者数 - 満足) ~ 単位数,
family = binomial, data = dat1)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.62166 0.75949 -4.769 1.86e-06 ***
単位数 0.11850 0.02367 5.007 5.54e-07 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.6268 on 8 degrees of freedom
Residual deviance: 6.3246 on 7 degrees of freedom
AIC: 30.394
Number of Fisher Scoring iterations: 4個別データを使用したロジスティック回帰
R
fit2 <- glm(
cbind(満足, 1-満足) ~ 単位数,
family=binomial,
data=dat2
)
summary(fit2)
Call:
glm(formula = cbind(満足, 1 - 満足) ~ 単位数, family = binomial,
data = dat2)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.62166 0.75949 -4.769 1.86e-06 ***
単位数 0.11850 0.02367 5.007 5.54e-07 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 138.59 on 99 degrees of freedom
Residual deviance: 101.29 on 98 degrees of freedom
AIC: 105.29
Number of Fisher Scoring iterations: 4