


データの準備と要約
僕が作った架空のデータで練習しましょう。単位数は5単位毎に設定してます。例題の内容や結果については色々とご意見があると思いますが、統計学の練習のためのサンプルですのでご了承ください。
例題 リハビリを受けている入院中の患者に対してリハビリに関する満足度調査を実施した。1週間に割り当てられた単位数をもとにランダムにインタビューした。「満足」と回答する割合と1週間のリハビリ単位数には関係があるのでしょうか?
データセット log01 をdat に読み込みます(ファイルの読み込み方)
dat <- read.csv("log01.csv", header=T, fileEncoding = "UTF-8")データの確認
View(dat)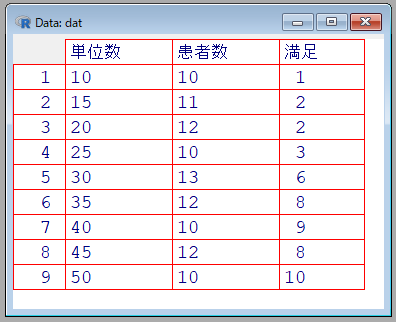
(満足=満足と回答した人数)
y軸を「満足と回答する確率」、x軸を「単位数」とします
g1 <- function(){
plot(満足/患者数~単位数, data=dat, ylab="満足と回答する確率")
}
g1()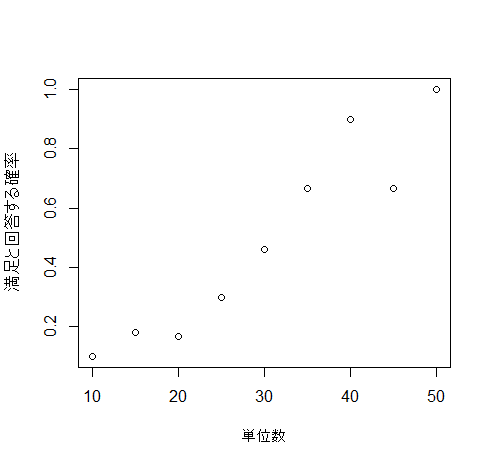
そのまま単回帰分析を実行して、回帰直線を挿入してみます
reg <- lm(満足/患者数~単位数, data=dat)
g1()
abline(reg)
#lines(range(dat$単位数), reg$coef[1] + reg$coef[2]*range(dat$単位数)) と同じ直線詳細は単回帰分析をご参照ください
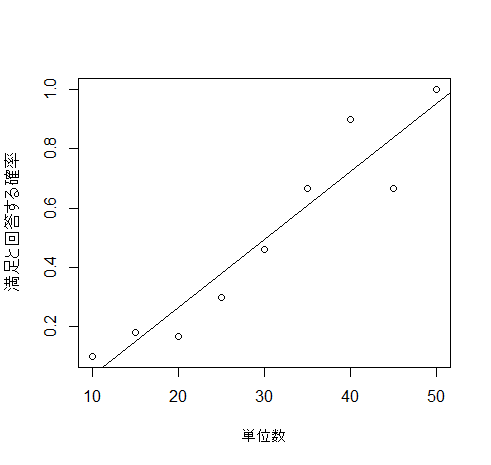
患者が満足と答える確率は0~1となるべきなのですが、回帰直線では0と1を突き抜けてしまいます
この直線では満足度とリハビリ単位数の関係が十分に説明できません
集計データ(満足数 vs 不満足数)を使用したロジスティック回帰分析
目的変数が連続変数で、誤差が「等分散の正規分布」に従うとは限らない場合、そのモデルは 一般化線形モデル(GLM) と呼ばれます。特に、目的変数が 0 または 1 のような二値データの場合は、データが 二項分布に従うと考えられるため、ロジスティック回帰モデルを用います。
R では、通常の線形回帰は lm(linear model)、一般化線形モデルは glm(generalized linear model)という関数で実行します。名前がよく似ているので、少しややこしく感じるかもしれません。
ロジスティック回帰で glm(..., family = binomial) を使うときに、2 列の行列を渡す場合は
cbind(成功数, 失敗数)
という形にします。今回の例では成功数=満足として扱います。
集計データ(満足数・不満足数)しかない場合は、以下のようなコードになります
fit <- glm(
cbind(満足, 患者数 - 満足) ~ 単位数,
family=binomial,
data=dat
)結果のまえに、この式のcbindの中を確認してみましょう
cbind(dat$満足, dat$患者数-dat$満足)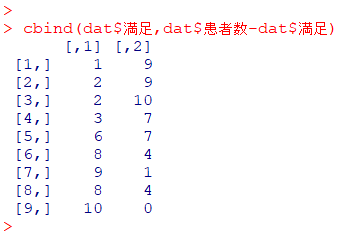
1単位から9単位までの満足と非満足の数が出力されました。
$\dfrac{1列目}{2列目}$ がオッズ比になっているのが分かります
結果
summary(fit)Call:
glm(formula = cbind(満足, 患者数 - 満足) ~ 単位数,
family = binomial, data = dat)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.62166 0.75949 -4.769 1.86e-06 ***
単位数 0.11850 0.02367 5.007 5.54e-07 ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.6268 on 8 degrees of freedom
Residual deviance: 6.3246 on 7 degrees of freedom
AIC: 30.394
Number of Fisher Scoring iterations: 4
ロジスティック回帰分析の結果、リハ単位数が増えると「満足」と回答する確率 $P$ が有意に上昇することが分かりました
リハビリ単位数が1週間に5単位上がると、満足と回答する割合のオッズが有意に$e^{0.1185}\fallingdotseq1.13$倍に上がる(13%アップ)ことを意味しています(理由は「結果の解釈」に記載してます)
傾向スコア
また、GLM(binomial)は 第1列(満足数)になる確率 p をモデル化 する仕組みです
$η=exp[−3.621+0.118×単位数]$
傾向スコア= $\dfrac{η}{1+η}$

結果のみでよければ、ここまででOKです