

(2, 3, 6, 7, 10) の平均と分散
5つのデータ(2, 3, 6, 7, 10)の平均値や分散について解説します。
$x_i ( i=1, 2, 3, 4, 5 )$
$x_i =\{2, 3, 6, 7, 10\} $
R
x <- c(2, 3, 6, 7, 10)
View(x)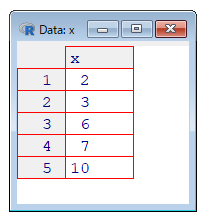
平均
$\overline{x_i}=\dfrac{\sum_{i=1}^{n}(x_i)}{n}$
R
sum(x) / length(x)> sum(x) / length(x)
[1] 5.6mean関数で平均値を求めます。
R
mean(x)> mean(x)
[1] 5.6二乗平均
$\dfrac{\sum_{i=1}^{n}(x_i^2)}{n}$
R
mean(x^2) > mean(x^2)
[1] 39.6分散(標本分散)
$\dfrac{\sum_{i=1}^{n}(x_i-\overline{x_i})^2}{n}$
$\dfrac{\sum_{i=1}^{n}x_i^2}{n}-\overline{x_i}^2$
R
sum((x - mean(x))^2) / length(x)
sum(x^2) / length(x) - (mean(x))^2> sum((x - mean(x))^2) / length(x)
[1] 8.24
> sum(x^2) / length(x) - (mean(x))^2
[1] 8.24不偏分散
$\dfrac{\sum_{i=1}^{n}(x_i-\overline{x_i})^2}{n-1}$
R
sum((x - mean(x))^2) / (length(x) - 1)> sum((x - mean(x))^2) / (length(x) - 1)
[1] 10.3var関数で不偏分散を求めます。
R
var(x)> var(x)
[1] 10.3標準偏差(標本標準偏差)
$\sqrt{x_iの標本分散}$
R
sqrt((1/length(x))*sum((x-mean(x))^2))
sqrt(sum(x^2) / length(x) - (mean(x))^2)> sqrt((1/length(x))*sum((x-mean(x))^2))
[1] 2.87054
> sqrt(sum(x^2) / length(x) - (mean(x))^2)
[1] 2.87054不偏標準偏差
$\sqrt{x_iの不偏標本分散}$
R
sqrt(sum((x - mean(x))^2) / (length(x) - 1))> sqrt(sum((x - mean(x))^2) / (length(x) - 1))
[1] 3.209361sd関数で求めます。
R
sd(x)> sd(x)
[1] 3.209361注意)Rの関数 sd は不偏標準偏差なので、標本標準偏差を求めるためには以下のようになります
R
sd(x)*sqrt((length(x)-1)/length(x))> sd(x)*sqrt((length(x)-1)/length(x))
[1] 2.87054色々な平均値
算術平均(相加平均):最も一般的な平均で、すべての数値の合計をその数の個数で割ることで計算されます。
幾何平均:数値の積の n 乗根です。R言語で幾何平均を計算する際には、自然対数の算術平均を求め、その平均の指数を取ることで幾何平均を求めます。正の数値に適用され、比率や成長率を表すデータに適しています。
調和平均:逆数の算術平均の逆数として計算されます。速度や比率の平均を求めるのに適しています。
加重平均:各データ点に重み(重要度や頻度など)をつけて平均を取ります。
刈り込み平均:極端な値を両端から除外してから平均を計算します。
R
# Arithmetic Mean
mean(x)
# Geometric Mean
exp(mean(log(x)))
# Harmonic Mean
length(x) / sum(1/x)
# Weighted Mean, weights w <- c(1, 2, 3, 2, 1) in this case
w <- c(1, 2, 3, 2, 1)
weighted.mean(x, w)
# Trimmed Mean, trim is the proportion to trim from each end (0 to 1)
mean(x, trim = 0.2)> # Arithmetic Mean
> mean(x)
[1] 5.6
> # Geometric Mean
> exp(mean(log(x)))
[1] 4.789389
> # Harmonic Mean
> length(x) / sum(1/x)
[1] 4.022989
> # Weighted Mean, weights w <- c(1, 2, 3, 2, 1) in this case
> w <- c(1, 2, 3, 2, 1)
> weighted.mean(x, w)
[1] 5.555556
> # Trimmed Mean, trim is the proportion to trim from each end (0 to 1)
> mean(x, trim = 0.2)
[1] 5.333333