

記述統計
要約
数値ベクトルの場合は、summary関数で要約。平均値、中央値、最大値、最小値、四分位点を求めることができる。
R
summary(pre_post)> summary(pre_post)
pre post
Min. :112.0 Min. :130.0
1st Qu.:121.0 1st Qu.:136.5
Median :130.0 Median :138.5
Mean :128.7 Mean :137.7
3rd Qu.:137.5 3rd Qu.:139.8
Max. :142.0 Max. :143.0 結果をワードやパワポにコピペする場合は、フォントで調整が必要になります。色々なフォントで試してみてください。
名義変数のみ抜き出したデータフレームの作成。
R
meigi <- data[ ,c("day", "time", "place")]
print(meigi)> print(meigi)
day time place
1 月曜日 AM 屋外
2 火曜日 PM 室内
3 水曜日 AM 室内
4 木曜日 AM 室内
5 金曜日 PM 屋外
6 土曜日 PM 室内名義変数の場合は、lapply関数で要約しておくと便利です。それぞれのデータに該当するサイズを求めることができる。
R
summary_meigi <- lapply(meigi, table)
print(summary_meigi)注意)データに日本語があると、ズレが生じます。
> print(summary_meigi)
$day
火曜日 金曜日 月曜日 水曜日 土曜日 木曜日
1 1 1 1 1 1
$time
AM PM
3 3
$place
屋外 室内
2 4
分割表(クロス表)
変数timeと変数placeは2値変数なので、分割表を作成することがでます。
R
table_data <- table(data$time, data$place)
print(table_data)> print(table_data)
屋外 室内
AM 1 2
PM 1 2R
table_data <- table(data$time, data$place)
View(as.data.frame.matrix(table_matrix))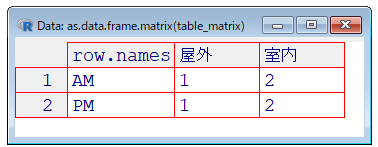
分割表ができたら、そのまま検定も可能です
R
fisher.test(table_data)> fisher.test(table_data)
Fisher's Exact Test for Count Data
data: table_data
p-value = 1
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
8.534046e-03 1.171777e+02
sample estimates:
odds ratio
1 層別解析
AM, PMのpre, postの平均値、標準偏差
R
# AMとPMごとにpreの平均値を計算
pre_means <- tapply(data$pre, data$time, mean)
# AMとPMごとにpostの平均値を計算
post_means <- tapply(data$post, data$time, mean)
# 結果の表示
print(round(pre_means, 1))
print(round(post_means, 1))> print(round(pre_means, 1))
AM PM
118.7 138.7
> print(round(post_means, 1))
AM PM
134.7 140.7 平均値と標準偏差を同時に求めたい場合
R
# 平均値と標準偏差を計算する関数を定義
calculate_stats <- function(x) {
c(mean = round(mean(x),1), sd = round(sd(x),1))
}
# AMとPMごとにpreの平均値と標準偏差を計算
pre_stats <- tapply(data$pre, data$time, calculate_stats)
# AMとPMごとにpostの平均値と標準偏差を計算
post_stats <- tapply(data$post, data$time, calculate_stats)
# 結果の表示
print("Pre statistics:")
print(pre_stats)
print("Post statistics:")
print(post_stats)> print("Pre statistics:")
[1] "Pre statistics:"
> print(pre_stats)
$AM
mean sd
118.7 6.1
$PM
mean sd
138.7 3.1
> print("Post statistics:")
[1] "Post statistics:"
> print(post_stats)
$AM
mean sd
134.7 4.2
$PM
mean sd
140.7 2.1