

実行方法のみ掲載
ターゲット(目的変数)が連続変数の場合
データの準備
データセット”reha_data”をdataに格納します(ファイルの読み込み)
data <- read.csv("reha_data.csv", header=T, fileEncoding = "UTF-8")
head(data)> head(data)
age sex preFIM duration postFIM
1 70 0 49 10 46
2 27 0 45 11 47
3 73 0 47 17 49
4 68 1 45 16 49
5 51 0 49 16 50
6 35 0 49 11 51sex : 0=女性, 1=男性
preFIM : リハビリ実施前のFIM
duration : リハビリの期間
postFIM : リハビリ実施後のFIM
使用するパッケージ(パッケージのインストール)
library(caret)
library(xgboost)
library(dplyr)合成データ生成モデル
ターゲット(目的変数)postFIMを特徴量(説明変数)に基づいて再定義します。
data <- data %>%
mutate(
postFIM = round(preFIM + duration * runif(nrow(data), 0.5, 1.5) - age * 0.2 + sex * 5 + rnorm(nrow(data), 0, 5))
)
head(data)(乱数を使用のため、postFIMは異なる結果になります)
age sex preFIM duration postFIM
1 70 0 49 10 45
2 27 0 45 11 47
3 73 0 47 17 44
4 68 1 45 16 61
5 51 0 49 16 62
6 35 0 49 11 56与えられた特徴量(preFIM, duration, age, sex)を用いて、新たな目的変数postFIMを合成的に生成しています。この操作は、データ分析や機械学習の実験で、モデルの振る舞いを検証する目的でよく使用されます。生成される postFIM は、preFIM、duration、age、sexおよびランダムノイズ(rnorm(nrow(data), 0, 5))の影響を受ける仮想的なアウトカムを表しています。duration に 0.5〜1.5 の一様乱数を掛け、age に負の係数を与え、sex に正の係数を与えることで、各要因が postFIM に及ぼす影響を表現しています。
- durationに0.5〜1.5の一様乱数を掛ける:リハビリの効果には個人差があるため、効果のばらつきをランダムに表現する目的で、現実のデータセットに見られるような不確実性や変動を模倣しています。
- ageに負の係数を与える:年齢が高いほど回復が困難になるという現実的な仮定に基づき、年齢が postFIM に負の影響を与えるように設定しています。
- sexに正の係数を与える:sex = 1 を男性、sex = 0 を女性。男性(1)の方が回復しやすいという仮定をモデル化しています。(これはあくまで実験目的の仮定であり、現実的には正ではないかもしれません)
予測がうまくいかない場合には、合成データ生成モデルを見直します。
学習データとテストデータ
createDataPartition関数によりデータセットを学習データ80%とテストデータ20%に分割します。
set.seed(123)
trainIndex <- createDataPartition(data$postFIM, p = 0.8, list = FALSE)
train_data <- data[trainIndex, ]
test_data <- data[-trainIndex, ]createDataPartition関数は、乱数を使用してデータを分割します。set.seed(123)を使用して生成された乱数のシードを設定し、再現性のある結果が得られるようにしています。
学習データとテストデータからXGBoostモデルの入力形式に適合するデータ構造を作成します。
train_matrix <- xgb.DMatrix(
data = as.matrix(train_data[, c("age", "sex", "preFIM", "duration")]),
label = train_data$postFIM)
test_matrix <- xgb.DMatrix(
data = as.matrix(
test_data[, c("age", "sex", "preFIM", "duration")]),
label = test_data$postFIM)xgb.DMatrix() 関数は、あらかじめ抽出・整形された特徴量(age、sex、preFIM、duration)と、対応する目的変数(postFIM)を受け取り、XGBoost内部で使用される最適化されたデータ形式(DMatrix)に変換します。生成された dtrain および dtest は、それぞれ学習データとテストデータをもとに作成された DMatrix オブジェクトです。この DMatrix 構造は、大規模なデータセットを効率的に処理するために設計されており、計算の高速化とメモリ使用の最適化を可能にします。また、スパースデータと密なデータの両方に対応しており、XGBoostはRだけでなく、Pythonなど他のプログラミング言語でも同様にこの形式を利用しています。
XGBoostのパラメータ設定
params <- list(
booster = "gbtree",
objective = "reg:squarederror",
eta = 0.1,
max_depth = 6,
subsample = 0.8,
colsample_bytree = 0.8
)booster: 使用するブースターのタイプを指定します。デフォルト”gbtree”は決定木を基にしたブースティングを行います。
objective: 学習の目的関数を指定します。これは 損失関数とも呼ばれ、モデルの予測値と実際の目的変数とのズレを数値化する関数です。”reg:squarederror” は回帰問題において平方誤差(Mean Squared Error)を用いることを意味し、予測値と実測値との差の二乗平均を最小化するようにモデルが学習されます。
eta: 学習率(learning rate)を指定します。この値は、各ブースティングステップでモデルの重みをどれだけ更新するか、すなわち「ステップサイズ」を決定します。値が小さいほど更新は緩やかになり、より多くのブースティングラウンドが必要になりますが、過学習を抑える効果があります。通常、0.01~0.3の範囲で設定されます。
max_depth: 各決定木の最大の深さを指定します。木の深さを大きくすると、より複雑な特徴量間の関係を学習できますが、その分、過学習のリスクも高くなります。
subsample: 各ブースティングステップでトレーニングに使用するデータのサンプル割合を指定します。値を1未満に設定することで、データの一部をランダムに抽出して学習を行い、過学習を抑える効果があります。一般的には 0.5~1 の範囲で設定されます。
colsample_bytree: 各決定木(ツリー)を構築する際に使用する特徴量の割合を指定します。ツリーごとに特徴量をランダムに抽出して使用することで、モデルの多様性が高まり、過学習を抑える効果があります。通常は 0.5~1 の範囲で設定されます。
学習データを使用した機械学習の実行
xgb_model <- xgb.train(
params = params,
data = train_matrix,
nrounds = 100,
watchlist = list(train = train_matrix, eval = test_matrix),
early_stopping_rounds = 10,
print_every_n = 10
)xgb.train : 指定されたパラメータと学習データに基づいてモデルが学習されます。
params: パラメータのセット。
data: 学習データを指定。
nrounds: モデルが学習データに対して繰り返し学習を行う回数(ブースティングラウンド数)を指定します。各ラウンドで1本の決定木が構築され、前の予測誤差を補うようにモデルが改善されていきます。
watchlist: 学習中にモデルの性能を評価するためのデータセットのリストです。通常、学習データとテストデータの両方を含めて指定し、各ブースティングステップでの性能指標(例:損失関数の値)をモニタリングします。これにより、モデルの過学習の兆候を把握し、early_stopping_roundsと組み合わせることで学習を自動的に停止させることができます。
print_every_n: 学習の進行状況(評価指標など)をどの程度の頻度で出力するかを指定します。この例では、10ラウンドごとにログが表示され、学習中のモデルの性能変化を確認できます。
モデルの予測精度の評価
RMSE(Root Mean Squared Error, 平均二乗平方根誤差):予測値と実際の値の差の二乗平均の平方根です。
MAE(Mean Absolute Error, 平均絶対誤差):予測値と実際の値の差の絶対値の平均です。MAEはRMSEと比べて外れ値の影響を受けにくいため、よりロバストな誤差の指標とされます。
R²(決定係数):相関係数の二乗。
# Evaluating Model Prediction Accuracy
# Predictions on Test Data
predictions <- predict(xgb_model, test_matrix)
# Evaluating the Model
true <- test_data$postFIM
# RMSE (Root Mean Squared Error)
rmse_val <- sqrt(mean((true - predictions)^2))
# MAE (Mean Absolute Error)
mae_val <- mean(abs(true - predictions))
# R² (Coefficient of Determination) already calculated
r2_val <- cor(true, predictions)^2
# Outputting the Results
cat("RMSE:", round(rmse_val, 2), "\n")
cat("MAE:", round(mae_val, 2), "\n")
cat("R²:", round(r2_val, 2), "\n")(乱数を使用のため、異なる結果になります)
> cat("RMSE:", round(rmse_val, 2), "\n")
RMSE: 10.12
> cat("MAE:", round(mae_val, 2), "\n")
MAE: 8.71
> cat("R²:", round(r2_val, 2), "\n")
R²: 0.85 モデルの重要度を取得し、重要度の高い順に並べて色分け
# Retrieve model importance
importance_matrix <- xgb.importance(model = xgb_model)
# Color based on the importance in descending order
num_features <- nrow(importance_matrix)
colors <- heat.colors(num_features)
# Plotting the importance
xgb.plot.importance(importance_matrix, col = colors)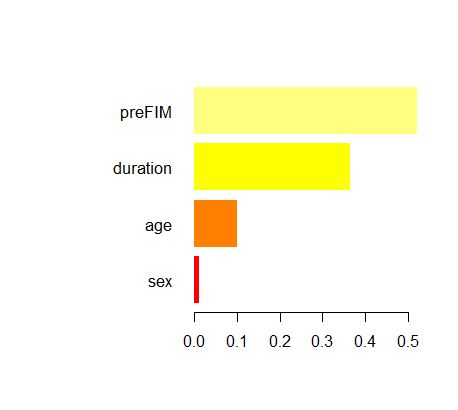
x軸の数値は特徴量の相対的な重要度を表し、モデルの予測におけるその役割の大きさを示しています。
予測
完成したモデルで、age = 65, sex = 0, preFIM = 30, duration = 60の場合のpostFIMを予測してみましょう
new_patient <- data.frame(
age = 65,
sex = 0,
preFIM = 30,
duration = 60
)
new_matrix <- xgb.DMatrix(data = as.matrix(new_patient))
prediction <- predict(xgb_model, new_matrix)
cat("Predicted postFIM:", round(prediction, 2), "\n")Predicted postFIM: 76.2 乱数を使用して、学習データとテストデータを作成しているので、答えは異なります。