


データの準備と要約
データセット cross3 をdatに格納します(ファイルの読み込み)
パッケージ makedummies のインストール(パッケージのインストールについて)
R
library(makedummies)datの先頭6行表示
R
head(dat)
変数をファクターに変更して要約を見てみます
R
dat$治療 <- factor(dat$治療)
dat$結果<- factor(dat$結果)
summary(dat)
基準を確認する(重要!)
R
str(dat)
先に記載されている方が基準となりますので、“治療あり“と”改善“が基準となります
分割表にした場合に、”治療あり”かつ”改善”の数が左上に表示されます
R
tab1 <- xtabs(~dat$治療+dat$結果)
print(tab1)
ダミー変数に変更(makedummies)
R
dat2 <- makedummies::makedummies(dat, basal_level = TRUE)
# :: の前にパッケージの名称を記載してます
head(dat2)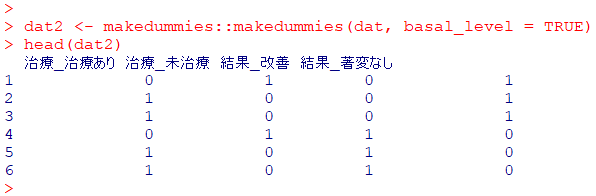
列名を変更します
R
colnames(dat2) <- c("治療あり", "未治療", " 改善", " 著変なし")
head(dat2)
ダミー変数を使った分割表
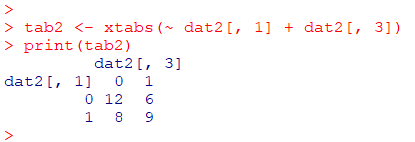
1列目と3列目を使用した場合の分割表を作成
行=治療あり(0=未治療、1=治療あり) 、列=改善(0=著変なし、1=改善)
R
tab2 <- xtabs(~ dat2[, 1] + dat2[, 3])
print(tab2)0, 1 の2値の場合 0 が基準となります
したがって、”未治療” かつ “著変なし” が左上に記載されます
2列目と4列目を使用した場合、行=未治療(0=治療あり、1=未治療) 、列=著変なし(0=改善、1=著変なし)となります
R
tab3 <- xtabs(~ dat2[, 2] + dat2[, 4])
print(tab3)0, 1 の2値の場合 0 が基準となります
今度は”治療あり” かつ “改善” が左上に記載されます
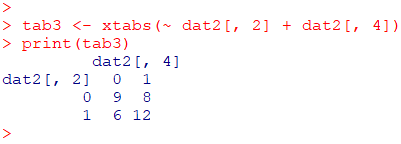
tab3 と tab3 は全く同じ分割表です
分割表は混乱しやすいので注意が必要です。特にダミー変数を扱う場合はゴチャゴチャになるので、何が基準になっているのかを必ず確認しておいてください。
実際の使い方
上記ことをしっかり理解したうえで、makedummiesを使用します
R
#重要なので再掲
print(tab1)
makedummiesのデフォルトでダミー変数を作った場合、上記と同じ分割表になります
R
dat3 <- makedummies(dat)
head(dat3)
R
tab4 <- xtabs(~ dat3[, 1] + dat3[, 2])
print(tab4)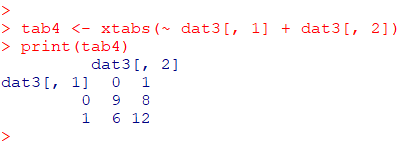
基準は、治療あり=0、改善=0 となっていることに注意してください