

F分布の性質
とする.このとき,
また,上側確率 $\alpha$ に対するパーセント点について,
が成り立つ.
分散比の信頼区間
ここで $f_\alpha$ は自由度 $(n_1 – 1, n_2 – 1)$ のF分布の上側 $\alpha$ パーセント点を表す.
自由度 $(m, n)$ のF分布の確率密度関数は
で与えられる.
ここでベータ関数 $B(\alpha, \beta)$ は
で定義される.
したがって,確率密度関数は
とも書ける.
期待値と分散
自由度を入れ替えた2つのF分布における臨界領域を示す.
R
par(mfrow=c(1,2))
curve(
df(x, 20, 10),
ylim=c(0, 1), xlim=c(0, 5),
xlab="", ylab="",
type="l",
main="F(20-1, 10-1)"
)
x <- qf(0.025, 20, 10) #0.360533
x1 <- seq(0, x, length = 100)
y <- df(x1, 20, 10)
polygon(
c(x1, rev(x1)),
c(rep(0, length(x1)),
rev(y)), col="pink"
)
curve(
df(x, 10, 20),
type = "l",
ylim = c(0, 1), xlim = c(0, 5),
xlab="",
ylab="",
main="F(10-1, 20-1)"
)
x <- qf(0.975, 10, 20) #2.773671
x1 <- seq(x, 5, length = 100)
y <- df(x1, 10, 20)
polygon(
c(x1,rev(x1)),
c(rep(0,length(x1)), rev(y)),
col="pink"
)
par(mfrow=c(1,1)) 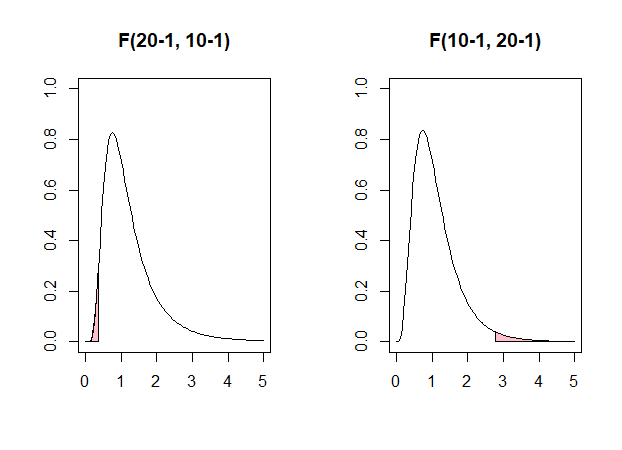
左図は $F(19,9)$ の下側 $2.5\%$ 領域,右図は $F(9,19)$ の上側 $2.5\%$ 領域を表している.
これらの領域は逆数の関係にあり,
が成り立つことを視覚的に確認できる.
Rによる検定の実行例
実際のデータに対しては,Rの var.test() 関数を用いることで,分散の等質性の検定を行うことができる.この関数はF検定に基づいて2群の母分散の等質性を検定し,検定統計量,p値,信頼区間などを出力する.
R
x1 <- c(6, 4, 5, 1, 9, 9, 3, 10)
x2 <- c(10, 12, 15, 13, 11, 9)
var.test(x1, x2) F test to compare two variances
data: x1 and x2
F = 2.2309, num df = 7, denom df = 5, p-value = 0.3941
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.3255279 11.7906623
sample estimates:
ratio of variances
2.230867分散比の95%信頼区間
F分布の性質より,
が成り立つ.
これを変形すると,
さらに整理して,
すなわち,
となる.
Rを使用して95%信頼区間を求める
R
x1 <- c(6, 4, 5, 1, 9, 9, 3, 10)
x2 <- c(10, 12, 15, 13, 11, 9)
#各群の不偏分散
(s1 <- var(x1))
(s2 <- var(x2))
n1 <- 8
n2 <- 6
#上側2.5%点(臨界値)
qf(1 - 0.05/2, n1 - 1, n2 - 1)
#下側2.5%点
qf(0.05/2, n1 - 1, n2 - 1)
lower <- (s1 / s2) / qf(1 - 0.05/2, n1 - 1, n2 - 1)
upper <- (s1 / s2) / qf(0.05/2, n1 - 1, n2 - 1)
#下限
lower
#上限
upper> x1 <- c(6, 4, 5, 1, 9, 9, 3, 10)
> x2 <- c(10, 12, 15, 13, 11, 9)
>
> #各群の不偏分散
> (s1 <- var(x1))
[1] 10.41071
> (s2 <- var(x2))
[1] 4.666667
> n1 <- 8
> n2 <- 6
>
> #上側2.5%点(臨界値)
> qf(1 - 0.05/2, n1 - 1, n2 - 1)
[1] 6.853076
> #下側2.5%点
> qf(0.05/2, n1 - 1, n2 - 1)
[1] 0.1892063
>
> lower <- (s1 / s2) / qf(1 - 0.05/2, n1 - 1, n2 - 1)
> upper <- (s1 / s2) / qf(0.05/2, n1 - 1, n2 - 1)
>
> #下限
> lower
[1] 0.3255279
> #上限
> upper
[1] 11.79066確率関数、期待値、分散
自由度 $(m, n)$ のF分布の確率密度関数は,ベータ関数 $B\left(\frac{m}{2}, \frac{n}{2}\right)$ を用いて
と表される.
ここでベータ関数とガンマ関数には
の関係がある.
したがって,確率密度関数はガンマ関数を用いて
本記事の作成にあたり、AIを用いて文章表現および構成の補助を行っています。掲載内容については管理者が確認・修正を行ったうえで公開しており、その内容に関する責任は管理者にあります。