

分散分析表の理解
データサイエンス入門ですので、分散分析表をもう少し詳しく見てみましょう
# Calculate the overall mean
overall_mean <- mean(data$data, na.rm = TRUE)
# Calculate the mean for each group
group_means <- data %>%
group_by(age = factor(age, levels = c("65-70", "70-75", "75-80"))) %>%
summarise(mean_value = mean(data, na.rm = TRUE))
# Create the scatter plot and add lines for the mean values
p <- ggplot(data, aes(x = factor(age, levels = c("65-70", "70-75", "75-80")), y = data)) +
geom_point() +
geom_hline(yintercept = overall_mean, color = "red", linetype = "dashed", size = 1) + # Overall mean
annotate("text", x = 1, y = overall_mean, label = sprintf("%.2f", overall_mean),
hjust = 0.5, vjust = -0.5, color = "red", size = 3.5) +
geom_hline(data = group_means, aes(yintercept = mean_value), color = "blue", size = 1) + # Mean for each group
geom_text(data = group_means, aes(x = age, y = mean_value, label = sprintf("%.2f", mean_value)),
position = position_dodge(width = 0.75), hjust = 1.2, vjust = 1, color = "blue", size = 3.5, check_overlap = TRUE) +
labs(x = "Age", y = "Data", title = "") +
theme_minimal()
# Display the scatter plot
print(p)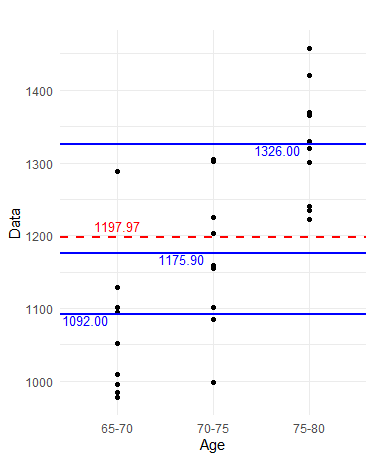
平方和 (square sum, sum of squares)
平方和(偏差\(^2\)の和)はテキストによって様々な書き方がありますが、ここでは以下の名称を使用します
- 全体平方和
- 群平方和
- 群内平方和(残差平方和)
下記の図のなかのそれぞれの偏差\(^2\)を足し合わせた合計になります。65-70歳をA群、70-75歳をB群、75-80歳をC群とします。A群、B群、C群は独立したサンプルです(ここ重要です)。
\(i=1,\, 2,\, 3\)
- \(i=1=A\)
- \(i=2=B\)
- \(i=3=C\)
なんだかややこしいのですが数式を組み立てるための準備です…最初から1群、2群、3群とすればこの手間は除けますがやや意味合いが異なってきます
\(j=1,\cdots,n_i\) (\(n_1=10, \, n_2=10, \, n_3=10\))
データ:\(y_{ij}\) (例えば \(y_{ij}=y_{27}\) はB群の7番目となります)
各群の平均:\(\bar{y_i}\)
全体の平均:\(\bar{y}=1197.967\)
mean(data$data)> mean(data$data)
[1] 1197.967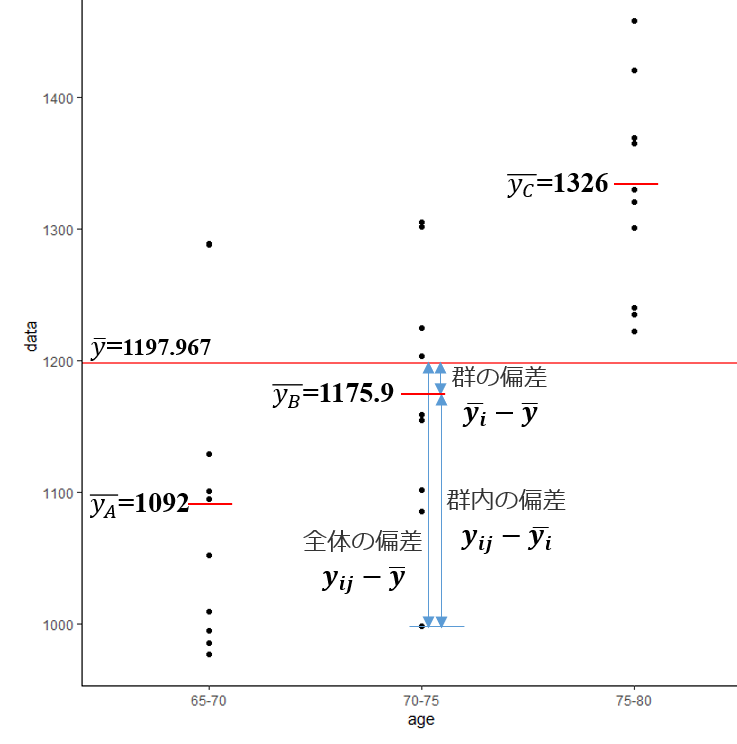
群平方和の偏差は各群に1つです。例えば、A群の群平方和=(A群の偏差\(^2\) ✕ n1)となります。数式になったら分かりずらいのですが、群平方和=(A群の偏差\(^2\) ✕ n1)+ (B群の偏差\(^2\) ✕ n2)+ (C群の偏差\(^2\) ✕ n3)となります。

全体平方和\(\displaystyle= \sum_{i = 1}^{3} \sum_{j = 1}^{n_i} (y_{ij}-\bar{y})^2\)
(自由度:\(n-1=29\))
群平方和$\displaystyle= \sum_{i = 1}^{3} \sum_{j = 1}^{n_i} (\bar{y_{i}}-\bar{y})^2=\sum_{i = 1}^{3} n_i(\bar{y_{i}}-\bar{y})^2=140542$
(自由度:\(群の数-1=2\))
群内平方和(残差平方和)$\displaystyle= \sum_{i = 1}^{3} \sum_{j = 1}^{n_i} (y_{ij}-\bar{y_i})^2=9714$
(自由度:\(n-群の数=27\))
分散分析では群平方和と群内平方和を使います。分散分析表には、全体平方和の出番はありません。でも、全体平方和=群平方和+群内平方和が成り立つことから、それぞれの平均平方和の比を検定して群間差を検証することになるので、全体平方和を改めて記載する場合もあります。
平方和の分解
全体平方和=群平方和+群内平方和を証明しておきましょう
ここで \(\bar{y_i}-\bar{y}=\alpha_i\) を群の効果、\(y_{ij}-\bar{y_i}=e_{ij}\) を残りの効果(残差)として考えます
$\blacksquare$ 一元配置分散分析の統計モデル
\({y_{ij} = \bar{y}+\alpha_i+e_{ij}}\)
グラフから 全体の偏差 = 群の偏差 + 群内の偏差 ということが理解できます。数式に直すと以下のようになります。
\((y_{ij}-\bar{y}) = (\bar{y_i}-\bar{y}) + (y_{ij}-\bar{y_i})\)
統計モデルを書き直すと、こうなります
\((y_{ij}-\bar{y}) = \alpha_i+e_{ij}\)
両辺の二乗和を求めてみましょう(例題のi=1,2,3を適用してます)
\(\displaystyle \sum_{i=1}^{3}\sum_{j=1}^{n_i}(y_{ij}-\bar{y})^2\)
\(\displaystyle =\sum_{i=1}^{3}\sum_{j=1}^{n_i}(\alpha_i+e_{ij})^2\)
\(\displaystyle =\sum_{i=1}^{3}\sum_{j=1}^{n_i}(\alpha_i^2+2\alpha_ie_{ij}+e_{ij}^2)\)
ここで残差の和は0になることから
(\(\displaystyle \sum_{i=1}^{3}\sum_{j=1}^{n_i}e_{ij}=0)\)
\(\displaystyle \sum_{i=1}^{3}\sum_{j=1}^{n_i}(y_{ij}-\bar{y})^2=\sum_{i=1}^{3}\sum_{j=1}^{n_i}(\alpha_i^2+e_{ij}^2)\)
つまり
\(\displaystyle \sum_{i=1}^{3}\sum_{j=1}^{n_i}(y_{ij}-\bar{y})^2= \sum_{i = 1}^{3} n_i(\bar{y_{i}}-\bar{y})^2+\sum_{i = 1}^{3} \sum_{j = 1}^{n_i} (y_{ij}-\bar{y_i})^2\)
証明終わり
分散分析の検定方法
帰無仮説:\(\alpha_1=\alpha_2=\alpha_3\)
平方和から平均平方和を算出し、群平均平方和と残差平均平方和の比がF分布に従うことを利用して検定します
統計量:\(F=\dfrac{群の平均平方和}{群内の平均平方和(残差平均平方和)}\)
\(\displaystyle F \sim F_{群の平方和の自由度、群内の平方和の自由度}\)
例題のF値は \(F_{2、27}\) に従います
\(F > F_{2, 27}(0.95)\) となる場合には帰無仮説が棄却される検定です
群の平均平方和=\(\dfrac{群の平方和}{自由度}=\dfrac{群の平方和}{2}\)
群内の平均平方和(残差平均平方和)=\(\dfrac{群内の平方和}{自由度}=\dfrac{群内の平方和}{27}\)

群の平均平方和(gun)
gun <- sum(
(mean(data[data$age=="65-70", "data"]) - mean(data$data))^2*10 +
(mean(data[data$age=="70-75", "data"]) - mean(data$data))^2*10 +
(mean(data[data$age=="75-80", "data"]) - mean(data$data))^2*10
)/2
print(gun)> print(gun)
[1] 140542dat[dat$age==”65-70″, “data”]
これはdatというデータフレームのage列が65-70に該当する対象者のdata列の値を抜き出したいときに使います。便利ですよ!
残差平均平方和(zan)
zan <- sum(
(data[data$age=="65-70", "data"] - mean(data[data$age=="65-70", "data"]))^2 +
(data[data$age=="70-75", "data"] - mean(data[data$age=="70-75", "data"]))^2 +
(data[data$age=="75-80", "data"] - mean(data[data$age=="75-80", "data"]))^2
)/27
print(zan)> print(zan)
[1] 9713.885F値
統計量$F$
gun/zan> gun/zan
[1] 14.46816F分布の95%分位点(上側)を求める関数。gunの自由度2、zanの自由度27。
#The function to find the 95th percentile (upper tail) of the F-distribution.
qf(0.95, 2, 27)> qf(0.95, 2, 27)
[1] 3.354131\(F > F_{2, 27}(0.95)\)となるので帰無仮説は棄却されます
p値
F統計量に対するF分布の上側確率
# the upper tail probability of the F-distribution for a given F statistic.
pf(14.468, 2, 27, lower.tail=F)> pf(14.468, 2, 27, lower.tail=F)
[1] 5.365088e-05分散分析表のp値と同じ値になっていますね!