


データの準備と要約
ダウンロードした note.txt は作業フォルダに保存してください
MeCabのインストール
以下のサイトからMeCabをインストールします

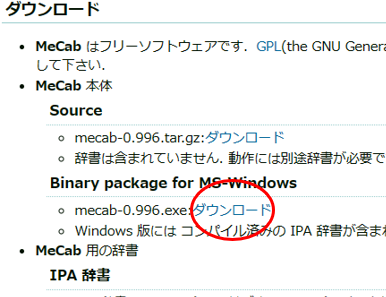
MeCabは 京都大学情報学研究科−日本電信電話株式会社コミュニケーション科学基礎研究所 共同研究ユニットプロジェクトを通じて開発されたオープンソース 形態素解析エンジンです。 言語, 辞書,コーパスに依存しない汎用的な設計を 基本方針としています。 パラメータの推定に Conditional Random Fields (CRF) を用 いており, ChaSenが採用している 隠れマルコフモデルに比べ性能が向上しています。また、平均的に ChaSen, Juman, KAKASIより高速に動作します。 ちなみに和布蕪(めかぶ)は, 作者の好物です。
MeCab
MeCabがインストールされているか確認します
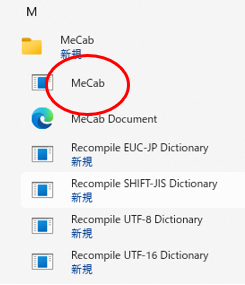
MeCab をクリックして、適当な日本語入力してみてください
ここでは「こんにちは、今日は統計学の勉強をしましょう」
と入力してみます
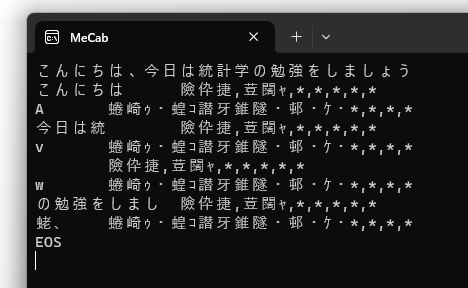
文字化けしますが、この表示がでれば MeCab が正常にインストールされています
RMeCabのインストール
RMeCabは、石田基広先生作のRパッケージです
R から日本語形態素解析ソフトである MeCab をバックグランドで操作するためのインターフェイス です
RMeCab をインストールします(Rのパッケージインストール)
install.packages("RMeCab", repos = "http://rmecab.jp/R")
library(RMeCab)RMeCabがインストールされたかどうかを確認します
dat_1 <- RMeCabFreq("note.txt")
View(dat_1)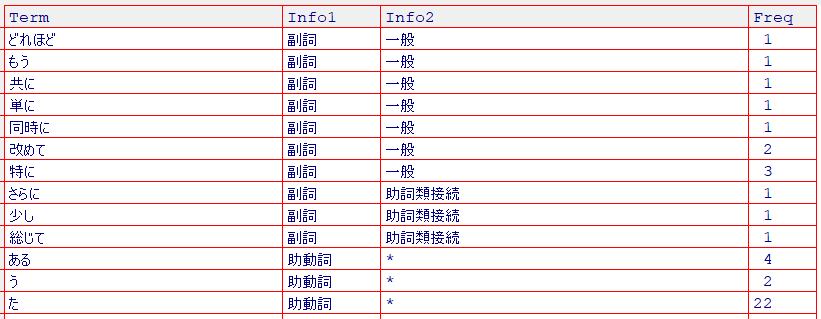
dat_1の全体を見て、必要な言葉のみにします
ここでは、datの名詞、動詞、形容詞を抜き出して、dat_2に格納します
dat_2 <- subset(
dat_1, Info1 == c("名詞", "動詞", "形容詞")
)代名詞、副詞可能、接尾、非自立を除外
dat_3 <- subset(
dat_2, !Info2 %in% c("代名詞", "副詞可能", "接尾", "非自立", "形容動詞語幹")
)Rのコードで分からないことはChatGPTに質問しましょう!
ChatGPTへの質問内容
dat_3 <- subset(dat_2, !Info2 %in% c("代名詞", "副詞可能", "接尾", "非自立"))
このRコードを詳しく教えてください。特に、!、%in%の部分をお願いします。
dat_3を確認して、「する」、「なる」を除外することにしました
dat_4 <- subset(
dat_3, !Term %in% c("する", "なる")
)wordcloud
パッケージwordcloudをインストールします(Rのパッケージインストール)
install.packages("wordcloud")
library(wordcloud)1回以上出現している単語(全単語)
pattern <- brewer.pal(8, "Dark2")
wordcloud(
dat_4$Term, dat_4$Freq, min.freq = 1, colors = pattern
)
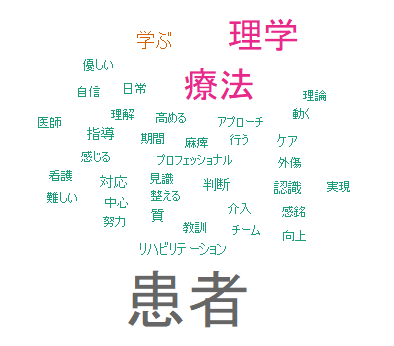
文字を全て横書きで表示
pattern <- brewer.pal(8, "Dark2")
wordcloud(
dat_4$Term, dat_4$Freq, min.freq = 1, colors = pattern, rot.per = 0
)
2回以上出現した単語を表示
pattern <- brewer.pal(8, "Dark2")
wordcloud(
dat_4$Term, dat_4$Freq, min.freq = 2, colors = pattern, rot.per = 0
)