

データの準備と要約
僕が作った架空のデータで練習しましょう。結果についてはご意見があると思いますが、統計学の練習のためのサンプルですのでご了承ください。
例題)回復期病棟に入院した脳卒中患者を対象としました。FIM利得(退棟時 FIM-入棟時 FIM)を入棟時のFIM、入院期間の理学療法の時間、入棟時のBMIで予測します
データセット jukaiki をdatに格納します(ファイルの読み込み)
csvファイルを直接開くと文字化けしています。Rでファイルを読み込んで使用してください。
使用するパケージ
library(tidyverse)
library(BlandAltmanLeh)head(dat)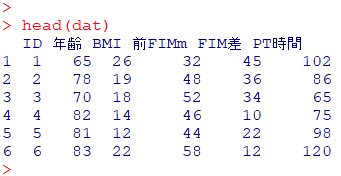
dim(dat)n=50, 5変数からなるデータセット

FIM差:退棟時 FIM-入棟時 FIM
BMI:入棟時のBMI
前FIMm:入棟時のFIM運動項目得点
PT時間:入院期間に理学療法を実施した時間
n=49
目的変数をFIM差として、説明変数を前FIMm、PT時間、BMIとした重回帰分析をRで実行してみましょう(関数lmは単回帰と同じです)
目的変数の分布を確認してみましょう
hist(dat$FIM差)
もし残差に偏りがあるのであれば再考しなければなりません
重回帰分析
fit <- lm(
FIM差 ~ BMI + 前FIMm + PT時間 ,
data=dat
)
summary(fit)
前FIMmとPT時間のp値は<0.05ですので、この2つの変数でFIM差を予測する予測式が成立します。p>0.05になったBMIについては吟味しなければなりません。予測式を分かり易く書くと以下のようになります。
FIM差 = 31.48 – 0.51*前FIMm + 0.15*PT時間
僕が作ったデータを使っているので実際にはあり得ませんが、上記の予測式を解釈すると・・・「入棟時のFIM運動項目が1点上がるとFIM利得は0.51低くなる・・・これは天井効果も考えられると思いますが、入棟時の得点が低いと伸びしろが大きいと考えられます。また入棟時の運動機能を考慮した場合でも、PT時間が1時間増えるとFIM利得は0.15増加するようです。」というようなことが研究計画に応じて考察できます。(ややPTに肩入れしたデータになっていますね・・・すみません)
これでRを使用した重回帰分析が実行できるようになりました
結果のみでよければ、ここまでです
ここらかはもう少し詳しく学習してみましょう
統計モデル
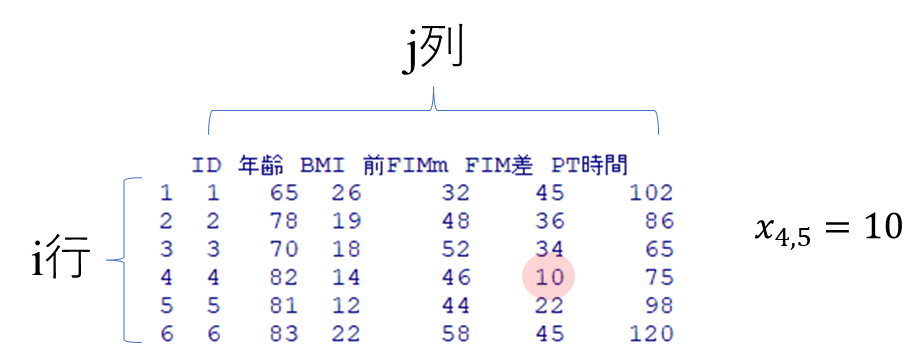
このサイトでは次のような標記に従います
$x_{i,j}$ の場合、$i$ はデータセットの行、$j$ はデータセットの列を示します
しかし統計モデルを書くときにはやや趣が異なりますのでご理解ください。今回の例では、重回帰分析によりFIM差を予測することが目的です。統計モデルは以下のようになります。
$\hat{y_i}=\beta_0+\beta_1x_{i1}+ \dotsc +\beta_jx_{ij}+e_{i} \qquad e_{i} \sim N(0,\sigma^2)$
ここで重要なのは誤差が正規分布に従うことを仮定していることです
$e_{i} \sim N(0,~\sigma^2)$
つまり 残差=$y_i-\hat{y_i}$ は正規分布に従うことを仮定して分析が進んで行きます
回帰分析後の残差分析は重要ですね。残差分析はあとで説明します。
今回の例では
$\hat{y_i}=\beta_0+\beta_1x_{i1}+ \dotsc +\beta_jx_{ij}+e_{i} \quad ( i=0,1,\dotsc,50, \quad j=5 )$
$\hat{} \quad$はハットと読み、FIM差の予測値を表します
重回帰分析の結果、以下のような予測式が成立しました
$\hat{y_i}=\beta_0+\beta_1x_{i1}+\beta_2x_{i2}+\beta_3x_{i3}$
$y_i$:サンプルのFIM差(実際のデータ)
$\hat{y_i}$:回帰式から予測されるFIM差(予測値)
FIM差$=y_i$
前FIMm$=x_{i1}$
PT時間$=x_{i2}$
BMI$=x_{i3}$
この書き方が苦手、よく理解できない・・・という人も多いかと思いますが、徐々に慣れてくると思います。
回帰係数の推定
単回帰分析や重回帰分析の係数の求め方のページにも記載しております。単回帰分析と同様に誤差二乗の総和が最小になるパラメタを推定します(最小二乗法)。
誤差二乗和=$\sum(y_i-(\beta_0+\beta_1x_{i1}+ \dotsc +\beta_jx_{ij}))^2$
これで $\beta_0 \sim \beta_j$ で偏微分して求めるのですが、線形代数で解いた方が簡単です
表記の定義:$x_{ij}$の場合、$i$はデータセットの行、$j$はデータセットの列を示す
$y_{i}=b_0+b_1x_{ij}+\dotsc+b_jx_{ij}+\varepsilon_{i} \quad i={1,2,\dotsc,n} \quad j={1,2,\dotsc,k}$
\(
\mathbf{X}=
\left(\begin{array}{ccc}
1 & x_{11} & \dotsc & x_{1k} \\
1 & x_{21} & \dotsc & x_{2k} \\
\vdots & \vdots & \ddots & \vdots \\
1 & x_{n1} & \dotsc & x_{nk}
\end{array}\right)
\)
\(
\mathbf{y}=
\left(\begin{array}{cc}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{array}\right)
\quad\)\(
\mathbf{b}=
\left(\begin{array}{cc}
b_0 \\
b_1 \\
\vdots \\
b_k
\end{array}\right)
\quad\)
とした場合、パラメタ推定の公式は以下のようになります
$\mathbf{b}=(\mathbf{X^T}\mathbf{X})^{-1}\mathbf{X^T}\mathbf{y}$
実際にdatのデータを挿入して求めてみましょう(ここではパイプ演算子を使って記述してみます)
mat <- dat %>%
mutate(b = c(rep(1, dim(dat)[1]))) %>%
select(b, BMI, 前FIMm, PT時間,) %>%
as.matrix()
solve(
t(mat) %*% mat) %*%
t(mat) %*%
dat$FIM差
# %*% この記号は行列の掛け算です
lm関数で算出した係数と同じ値を求めることができました