データの準備と要約
使用するパッケージ(パッケージのインストール)
library(ggplot2)
library(dplyr)データセット unif をdatに格納します(ファイルの読み込み).
サンプルデータの取り込み
setwd("C:\\Users\\rehay\\Documents\\back up folder\\統計学備忘録\\ブログで使用したサンプル")
getwd()
.libPaths("C:\\Users\\rehay\\Documents\\Rpackages")
dat <- read.csv("unif.csv", header=T, fileEncoding = "UTF-8")
head(dat)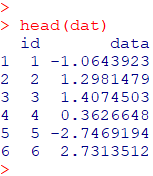
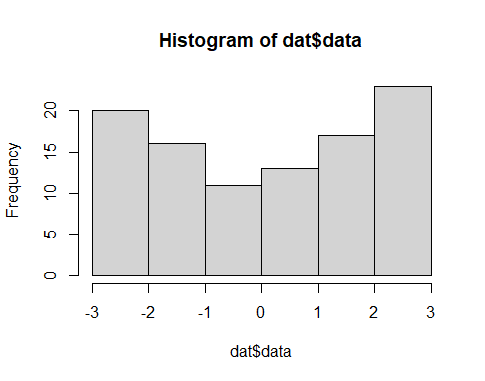
hist(dat$data)サンプルデータの unif は一様分布からの乱数です
検定
データセット unif についてKolmogorov-Smirnov 検定(コルモゴロフ・スミルノフ検定)とShapiro-Wilk検定を実行します。
帰無仮説:サンプルデータは指定された理論分布(ここでは正規分布)に従う
有意水準:5%
1標本のKolmogorov-Smirnov 検定(KS検定)
y=”pnorm” で正規分布を指定します
ks.test(
x=dat$data, y="pnorm",
mean=mean(dat$data),
sd=sd(dat$data)
)
p>0.05より、データが正規分布に従うという帰無仮説を棄却するには十分ではありません。従って「サンプルデータは正規分布から有意に逸脱しているとは言えない」という結果になりました。
2標本のKolmogorov-Smirnov検定では、2つのサンプルが同じ分布から抽出されたかどうかを検定します。異なるサンプルセットが同じ分布特性を持つかどうかを評価することができます。
Shapiro-Wilk検定
shapiro.test(x=dat$data)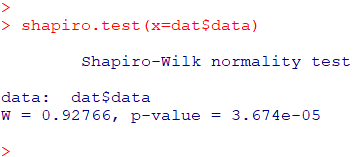
p<0.05より、データが正規分布に従うという帰無仮説が棄却されます。従って「サンプルデータは正規分布から有意に逸脱している」と考えられます。
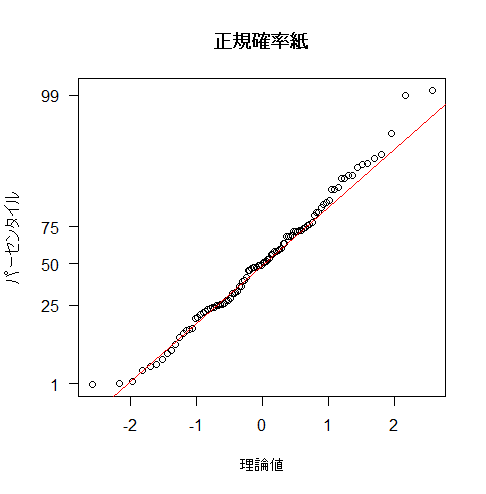
Kolmogorov-Smirnov検定とShapiro-Wilk検定では判定が異なります。ヒストグラムを見た限りでは、正規分布ではないようですので、Shapiro-Wilk検定が正しいようです。
Kolmogorov-Smirnov検定やShapiro-Wilk検定などの正規性検定は、小さなサンプルサイズの場合、第一種の過誤(帰無仮説を誤って棄却すること)を犯す確率が高まる傾向があります。また、サンプルサイズが大きくなると、わずかな正規性からの逸脱も検出する可能性があります。正規性を評価する場合は、上述した検定だけではなく、ヒストグラムやQQプロット(Quantile-Quantileプロット)などのグラフィカルな評価も必須です。