

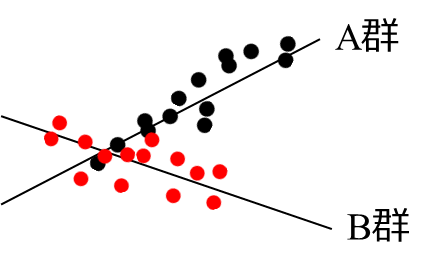
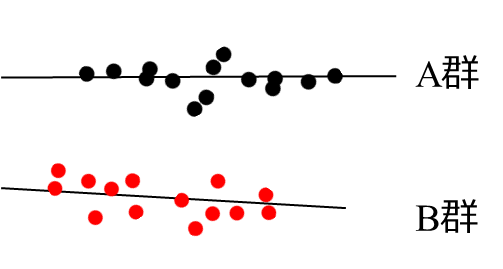
非並行性の検定(交互性の検定)
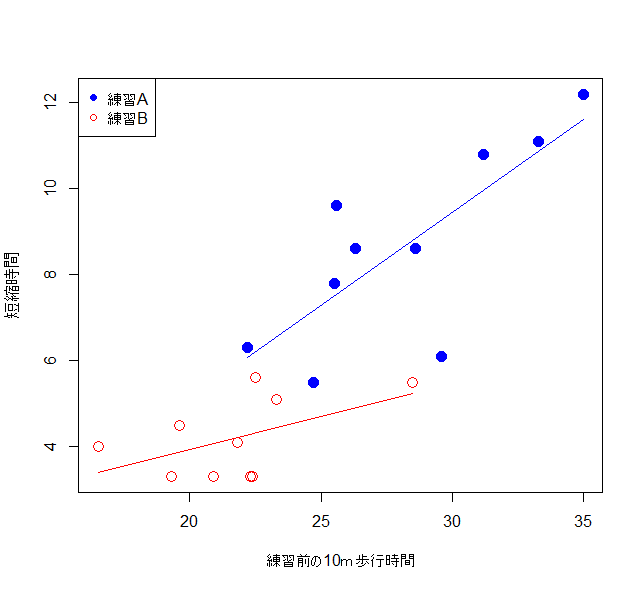
各群の回帰直線
非平行性の検定のp値が大きい場合には、両群の回帰直線の傾きが非平行であると判断される。この場合、両群に共通する回帰直線を仮定することは適切ではなく、それぞれの回帰式を個別に検討する必要がある。
非平行性の検定のp値が小さい場合には、両群の回帰直線の傾きは並行であると判断される。この場合には、共通する傾きを用いた回帰直線によって検証を行うことになる。
回帰分析および分散分析を用いて、並行性の検定を行う
fit2 <- lm(short ~ gait * pre, data=data)
summary(fit2)> summary(fit2)
Call:
lm(formula = short ~ gait * pre, data = data)
Residuals:
Min 1Q Median 3Q Max
-3.1653 -0.5919 0.2472 0.6316 2.0641
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.5320 2.8928 -1.221 0.239776
gaitB 4.4047 4.0947 1.076 0.298011
pre 0.4323 0.1016 4.254 0.000606 ***
gaitB:pre -0.2791 0.1668 -1.673 0.113726
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.242 on 16 degrees of freedom
Multiple R-squared: 0.8399, Adjusted R-squared: 0.8099
F-statistic: 27.98 on 3 and 16 DF, p-value: 1.334e-06という結果となり、交互作用は有意ではないと判断される
この結果から、歩行練習Aと歩行練習Bの回帰直線を求めることができる
歩行練習Aの切片$=-3.532$
歩行練習Bの切片$=-3.532+4.4047=0.8727$
歩行練習Aの傾き$=0.4323$
歩行練習Bの傾き$=0.4323-0.2791=0.1532$
結果
歩行練習A$=-3.532+0.4323*$歩行練習前の10m歩行時間
歩行練習B$=0.8727+0.1532*$歩行練習前の10m歩行時間
注意)回帰直線を描くこと自体は可能であるが、外挿による予測は行うことはできない。すなわち、結果を導出した標本の範囲内における予測に限定される。
anova(fit2)> anova(fit2)
Analysis of Variance Table
Response: short
Df Sum Sq Mean Sq F value Pr(>F)
gait 1 99.458 99.458 64.5044 5.27e-07 ***
pre 1 25.657 25.657 16.6403 0.0008738 ***
gait:pre 1 4.317 4.317 2.7996 0.1137261
Residuals 16 24.670 1.542
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1もちろん同じ 値となるが、 という結果となり、交互作用は有意ではないと判断される(この検定結果に基づいて両群の回帰直線の非平行性が判断される場合もある)。なお、交互作用項の平均平方和は、各群の回帰式と共通する傾きを仮定した回帰式の推定値から求めることができる(詳細は省略するが、参考図のみ示しておく)。
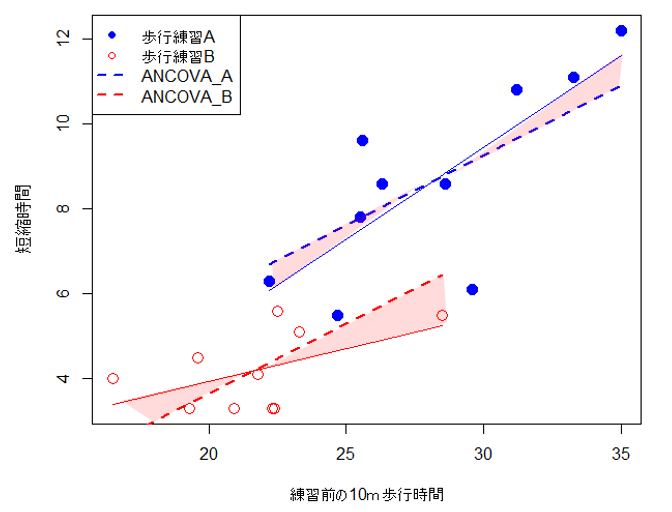
参考
両群に共通した回帰直線を求めるために、以下のような手順を行う

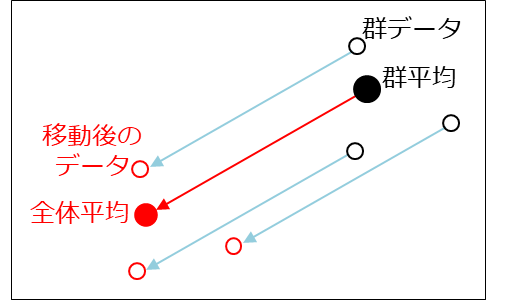
まず、歩行練習A群の平均を全体の平均まで移動させる(→)。次に、その移動量と同じだけデータ全体を平行移動する(→)。歩行練習B群についても同様の操作を行い、すべてのデータを移動させる。このようにして得られたデータから算出した回帰直線の傾きが、両群に共通する傾きとなる。
共通回帰の検定
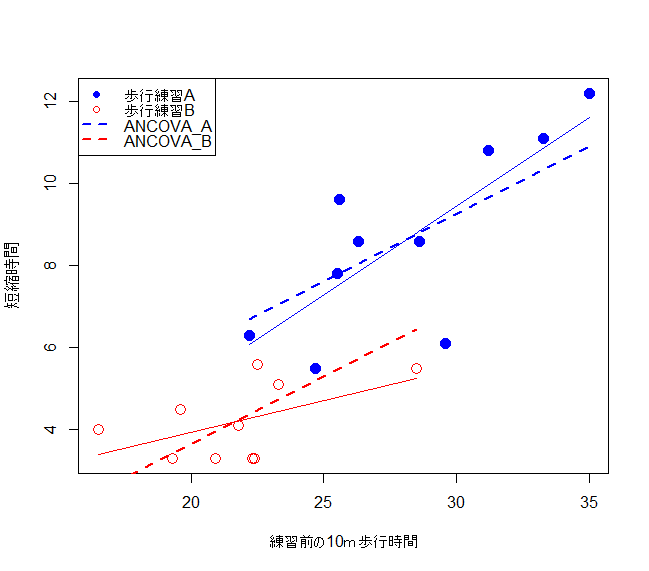
交互作用項が有意ではなかったため、共通回帰直線(点線)が意味をもつかどうかを検定する。これは、群間で共通の傾き(すなわち共通回帰直線)を用いることが妥当であるかどうかを統計的に検証するものである。
summary(fit)> summary(fit)
Call:
lm(formula = short ~ gait + pre, data = data)
Residuals:
Min 1Q Median 3Q Max
-3.0202 -0.7083 -0.0401 1.0303 1.7947
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.61018 2.42519 -0.252 0.80436
gaitB -2.32654 0.80219 -2.900 0.00996 **
pre 0.32873 0.08474 3.879 0.00121 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.306 on 17 degrees of freedom
Multiple R-squared: 0.8119, Adjusted R-squared: 0.7898
F-statistic: 36.69 on 2 and 17 DF, p-value: 6.797e-07この統計モデルにおけるF値は36.69であり、対応するp値は0.05未満(具体的には 6.797e−07)であることから、モデル全体が統計的に有意であると確認される。これは、モデルに含まれる予測因子が目的変数である歩行時間の短縮に対して有意な説明力を有していることを示すものである。特に、「pre」変数(練習前の10m歩行時間)のp値は0.00121であり、これは練習前の10m歩行時間が歩行時間の短縮に正の影響を与えていることを示している。以上の結果より、練習前の10m歩行時間は、歩行時間短縮を予測する上で重要な因子として考慮すべきであると結論づけられる。
F値の求め方(詳細は重回帰分析をご覧ください)
各群の共通回帰(赤および青の点線)から得られる推定値と、各群の平均値との差に基づく平均平方和を、残差の平均平方和で除したF値で検定を行う(平方和については分散分析、重回帰分析で解説している)。共通回帰のF値が大きい場合には、共通回帰が有意な説明力を有し、意味をもつものと解釈される。一方で、F値が小さい場合には、共通回帰の傾きが0に近いことを意味する。
# Predicted values of reduction time obtained from covariance analysis (fit)
yhat <- predict(fit)
# Sum of squares of the differences between the predicted values from the regression equation and the actual mean values
Sreg <- sum((yhat - mean(data$short))^2)
# Sum of squared residuals
Sres <- sum((yhat - data$short)^2)
# F-value = (Sreg/degrees of freedom) ÷ (Sres/degrees of freedom)
F <- (Sreg/2) / (Sres / (20 - 2 - 1))
print(F)
# F-test
pf(F, 2, 17, lower.tail=FALSE)> print(F)
[1] 36.68865
> # F-test
> pf(F, 2, 17, lower.tail=FALSE)
[1] 6.796902e-07共分散分析の結果と同じ値になりました
参考(いつもお世話になってます)
